《Neo4j权威指南》一
一 图数据库基础
1.1 图数据模型
图数据要具体存储到图数据库中,最终落实为具体的数据文件,自然就涉及特定的图数据模型,即如何存,采用什么实现方式来存。常用的有三种:==属性图、超图和三元图。
其中Neo4j就采用属性图模型,因为属性图直观更易于理解,能描述大部分图使用场景。符合下列特征的图数据模型就称为属性图。
- 它包含节点和关系
- 节点可以有属性(键值对)
- 节点可以有一个或多个标签
- 关系有名字和方向,并总是有一个开始节点和一个结束节点。
- 关系也可以有属性
超图是一种更为广义对图模型,在超图中,一个关系(称作超边)可以关联任意数量的节点,无论是开始节点端还是结束节点端,而属性图中一个关系只允许一个开始节点和一个结束节点。因此,超图更适用表示多对多关系。
1.2 图计算引擎
图数据库的核心也是构建在一个一起闹智商的,那就是图计算引擎,是能够组织存储大型图数据集并且实现了全局图计算算法的一种数据库核心构建。
它包含一个具有联机事务处理过程的数据库记录系统,图计算引擎用于响应用户终端允许时发来的查询请求,周期性从记录系统中进行数据抽取、转换和家在,然后将数据从记录数据系统读入到图计算引擎并进行离线查询和分析,最好将查询、分析的结果返回给用户终端。
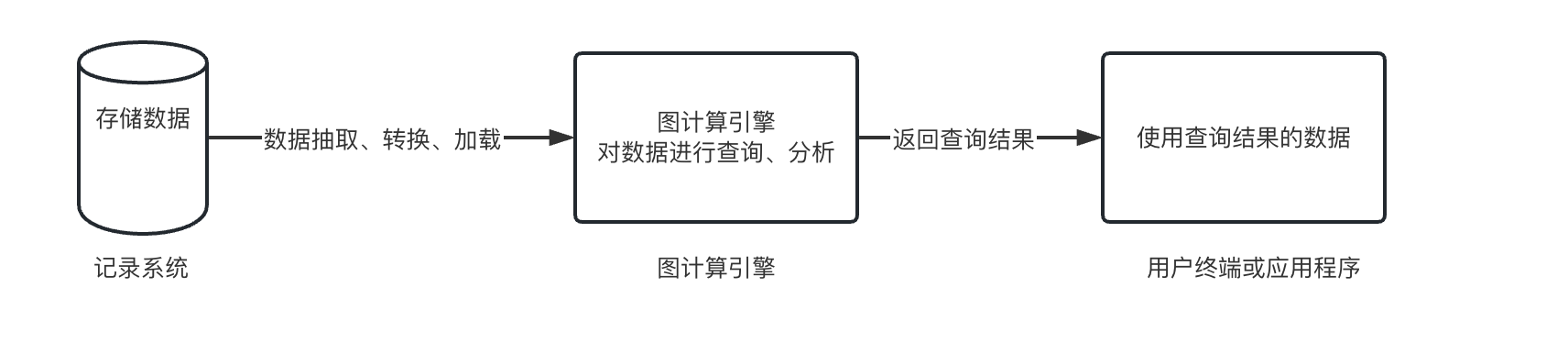
目前较为流程的图计算引擎有两种:单机图计算引擎和分布式图计算引擎。
1.3 Neo4j概述
Neo4j是由Java实现的开源的NoSQL图数据库。
1.4 Neo4j底层存储结构
免索引邻接是图数据库实现高效遍历的关键,那么免索引邻接的实现机制就是Neo4j底层存储结构设计的关键。能够支持高效的,本地化的图存储以及任意图算法的快速遍历,是使用图数据库的重要原因。
从宏观角度来说,Neo4j中仅仅只有两种数据类型:
- 节点(Node):节点类似E-R图中的实体,每一个实体可以有0个或多个属性,这些属性以key-value对的形式存在,属性没有特殊的类别要求,同时每个节点还具有相应的标签(Label),用来区分不同类型的节点。
- 关系(Relationship):关系也类似与E-R图中的关系。一个挂你想有起始节点和终止节点。关系也有自己的属性和标签。

节点和关系分别采用固定长度存储,节点存储文件用来存储节点的记录,文件名叫neostore.nodestore.db。节点记录的长度为固定大小,每个节点记录的长度为9字节。格式为:Node:inUse+nextRelId+nextPropId。
- inUse:1表示该节点被正常使用,0表示该节点被删除。
- nextRelId:该节点的下一个关系ID
- nextPropId:该节点的下一个属性ID
如果有一个ID为100的节点,就能直接计算出该记录在存储文件中的第900个字节。成本仅为O(1)。
关系存储文件用来存储关系的记录,文件名为neostore.relationshipstore.db。像节点的存储一样,关系存储区的记录大小也是固定的,格式为Relationshipstore:inUse+firstNode+secondNode+relType+firstPrevRelId+firstNextRelId+secondPrevRelId+secondNextRelId+nextPropId。
- inUse,nextPropId:作用同上
- firstNode:当前关系的起始节点
- secondNode:当前关系的终止节点
- relType:关系的类型
- firstPrevRelId & firstNextRelId:起始节点的前一个和后一个关系的ID
- secondPrevRelId & secondNextRelId+nextPropId:终止节点的前一个和后一个关系的ID
Neo4j中有一个.id文件用来保持对未使用记录对跟踪,用来回收未使用的空间。节点和关系的存储文件只关系图的基本存储结构而不是属性数据。这两种记录都使用固定大小的记录,以便存储文件内的任何记录都可以根据ID快速的计算出来。
下图是Neo4j中其他常见的基本存储类型,属性记录的物理存储放置在neostore.propertystore.db文件中。与节点和关系的存储记录一样,属性的存储记录也是固定长度。每个属性记录包含4个属性块和属性链中下一个属性的ID。属性链是单向链表,而关系链是双向链表。一个属性记录中可以包含任何JVM支持的基本数据类型、字符串、基于类型的数组以及属性索引文件(neostore.propertystore.db.index)。属性索引文件主要用于存储属性的名称,属性索引的值部分存储的是指向动态内存的记录或者内联值,短字符串和短数组会直接内联在属性存储记录中。当长度超过属性记录中的propBlock长度限制之后,会单独存储在其他的动态存储文件中。
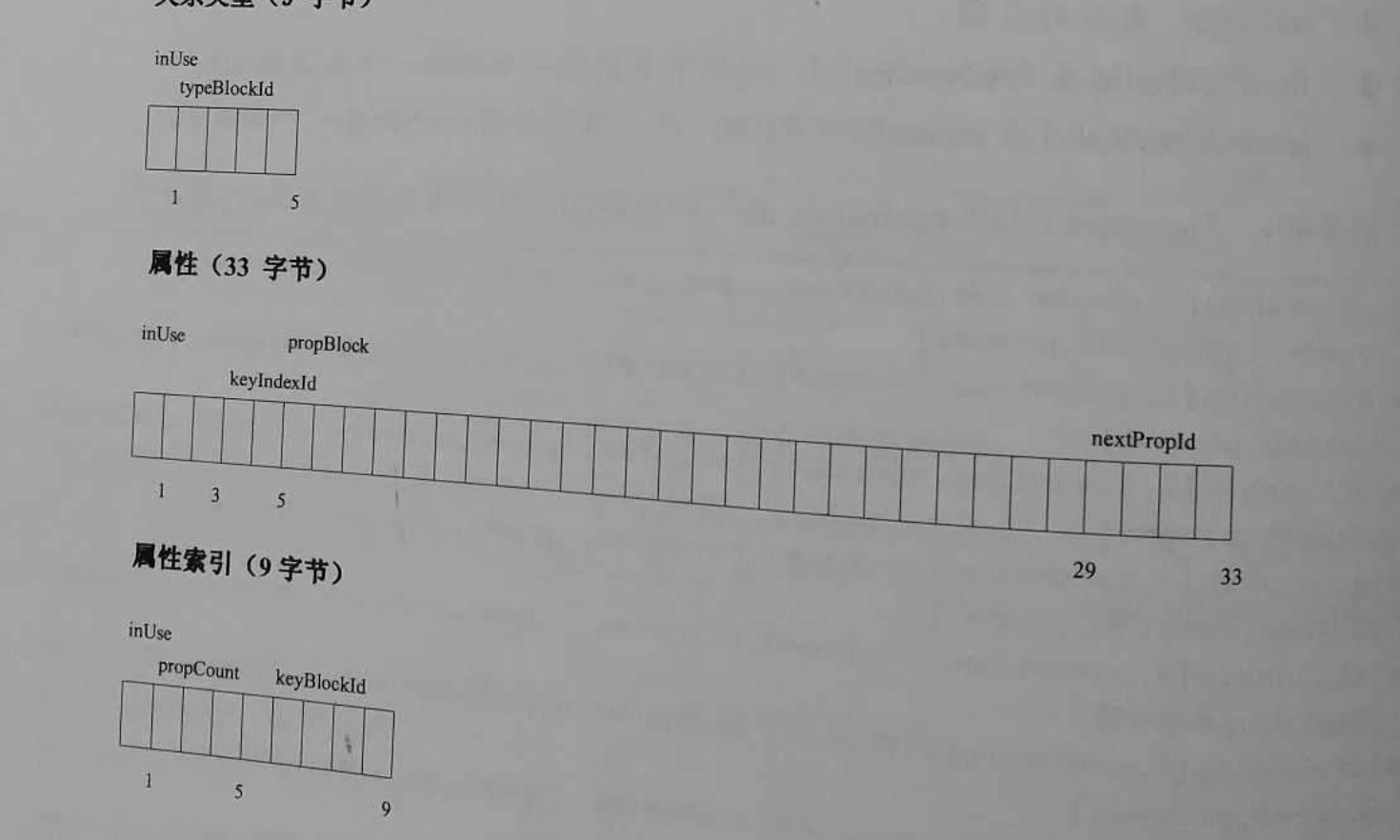
Neo4j中两种动态存储:动态字符串存储(neostore.propertystore.db.strings)和动态数组存储(neostore.propertystore.db.arrays)。动态存储记录是可以扩展的,如果一个属性长到一条动态存储记录仍然无法完全容纳时,可以申请多个动态存储记录逻辑上进行连接。
1.5 Neo4j的遍历方式
每个节点记录都包含一个指向该节点的第一个属性的指针和联系链中第一个联系的指针。要读取一个节点的属性,从指向第一个属性的指针开始,遍历整个单向链表的结构。要找到一个节点的关系,从指向的第一个关系开始,遍历整个双向链表,知道找到。一单找到我们就可以与使用和超找节点属性一样的方法查找关系的属性。我们也可以很方便的获取起始节点和结束节点的ID,利用节点ID就可以立即得到每个节点在节点存储文件中的具体位置,时间复杂度为O(1)。
下面通过一个例子来讲解遍历关系和节点的详细过程,假如在Neo4j中纯粹来ABCDE5个节点和R1、R2、R3、R4、R5、R6、R7 7个关系,它们之间的关系如下图所示。
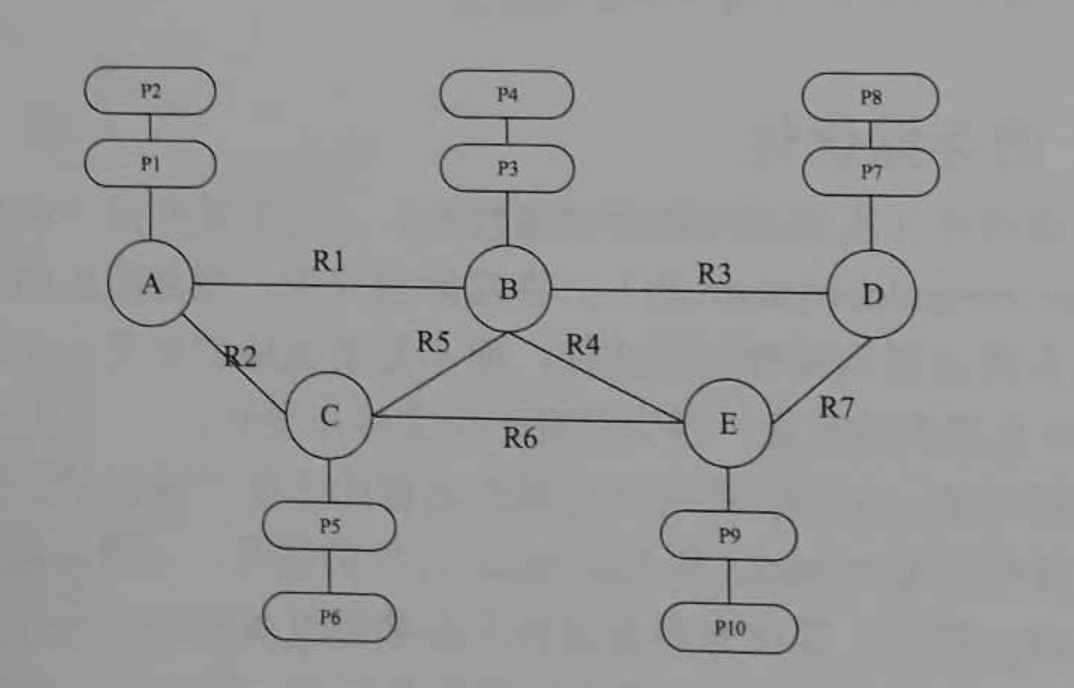
假如要遍历图中节点B的所有关系,只需要向NODEB-NEXT方向遍历,直到指向NULL为止。如下图所示,可以看出即节点B的所有关系为R1、R3、R4、R5。
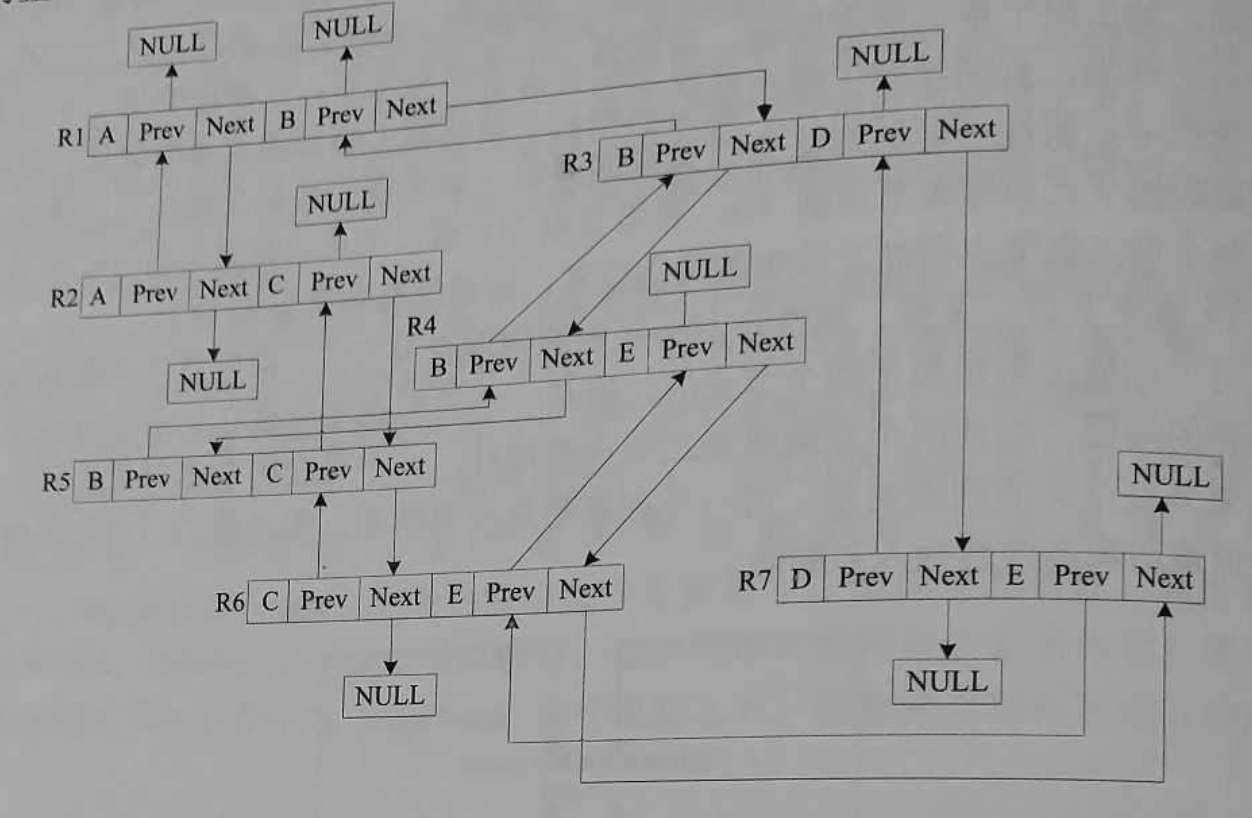
通过固定大小的存储记录和指针ID,只要跟随指针就可以简单的实现遍历并且告诉指向。要遍历一个节点到另一个节点的特定关系,在Neo4j中只需要遍历几个指针。
- 从一个给定节点定位关系链中第一个关系的位置,可以通过计算它在关系存储的偏移量来获得。跟获得节点存储位置的方法一样,使用关系ID乘以关系记录的固定大小即可找到关系在存储文件中的正确位置。
- 在关系记录中,搜索第二个字段可以找到第二个节点的ID,用节点记录大小乘以节点ID可以得到节点在存储中的正确位置。
1.6 Neo4j的存储优化
Neo4j支持存储优化(压缩和内联存储属性值),对于某些段字符的属性可以直接存储在属性文件中,而不是单独的放到另一个动态存储区,这样可以减少I/O操作并增加吞吐量。
Neo4j还可以对属性名称的空间严格维护。属性名称都通过属性索引文件从属性存储中间接引用。属性索引允许所有具有想用名称的属性共享单个记录,因而可以节省相当大的空间和I/O开销。
Neo4j采用缓存策略,保证那些经常访问的数据可以快速地被多次重复访问。Neo4j高速缓存的页面置换算法是基于最不经常使用的页置换(LFU)缓存策略,即使有些页面近期没有使用过,但是因为以前的使用频率很高,那么在短期之内它页不会被淘汰。
二 Neo4j 基础入门
2.1 安装部署
步骤一:安装对应版本JDK
步骤二:🔗官网下载
初始用户名、密码均为neo4j,安装好后,具体文件目录如下:

其中bin目录为运行目录,下面为启动关闭命令:
./neo4j start
./neo4j stop
启动完毕后,本地访问地址默认为:http://localhost:7474/browser/
2.2 Neo4j 中基本元素与概念
2.2.1 节点
节点(Node)是图数据库中的一个基本元素,用以表示一个实体记录,就像关系数据库中的一条记录一样。在Neo4j中节点可以包含多个属性和多个标签。
2.2.2 关系
关系(Relationship)是图数据库中的一个基本元素。当数据库汇中已经存在节点后,需要将节点连接起来构成图。关系就是用来连接两个节点,也称为图论的边(Edge),其始端和末端都必须是节点,关系不能指向空也不能从空发起。关系和节点一样可以包含多个属性,但是关系只能有一个类型(Type)。
关系必须有开始节点和结束节点。两头都不能为空。节点可以被关系串联或并联起来,由于关系是有方向的,所以可以在由节点、关系组成的图中进行遍历操作。
在图的遍历操作中我们可以指定关系遍历的方向或者指定为无方向,因此在创建关系时不必为两个节点创建相互指向的关系,而是在遍历时不指定遍历方向即可。特别注意一个节点可以存在指向自己的关系。
2.2.3 属性
属性是由键值对组成的,就像hash表一样,属性名类似变量名,属性值类似变量值。属性值可以是基本的数据类型,或者由基本数据类型组成的数组。
属性值没有null的概念,如果一个属性不需要了可以直接将整个键值对都移除,在查询时,可以用IS NULL关键字判断属性是否存在。
| 类型 | 说明 | 取值范围 |
|---|---|---|
| boolean | 布尔值 | true/false |
| btye | 8位的整数 | -128~127,inclusive |
| short | 16位的整数 | |
| int | 32位的整数 | |
| long | 64位的整数 | |
| float | 32位的浮点数 | |
| double | 64位的浮点数 | |
| char | 16位的无符号整数代表的字符 | |
| string | Unicode字符序列 |
2.2.4 路径
当使用节点和关系创建了一个图后,在此图中任意两个节点间都说可能存在路径的。路径也有长度的概念,也就是路径中关系的条数,单独一个节点也可以组成长度为0的路径。
2.2.5 遍历(Traversal)
遍历的规则可以是广度优先。也可以是深度优先。
2.3 官方实例入门
2.3.1 创建图数据
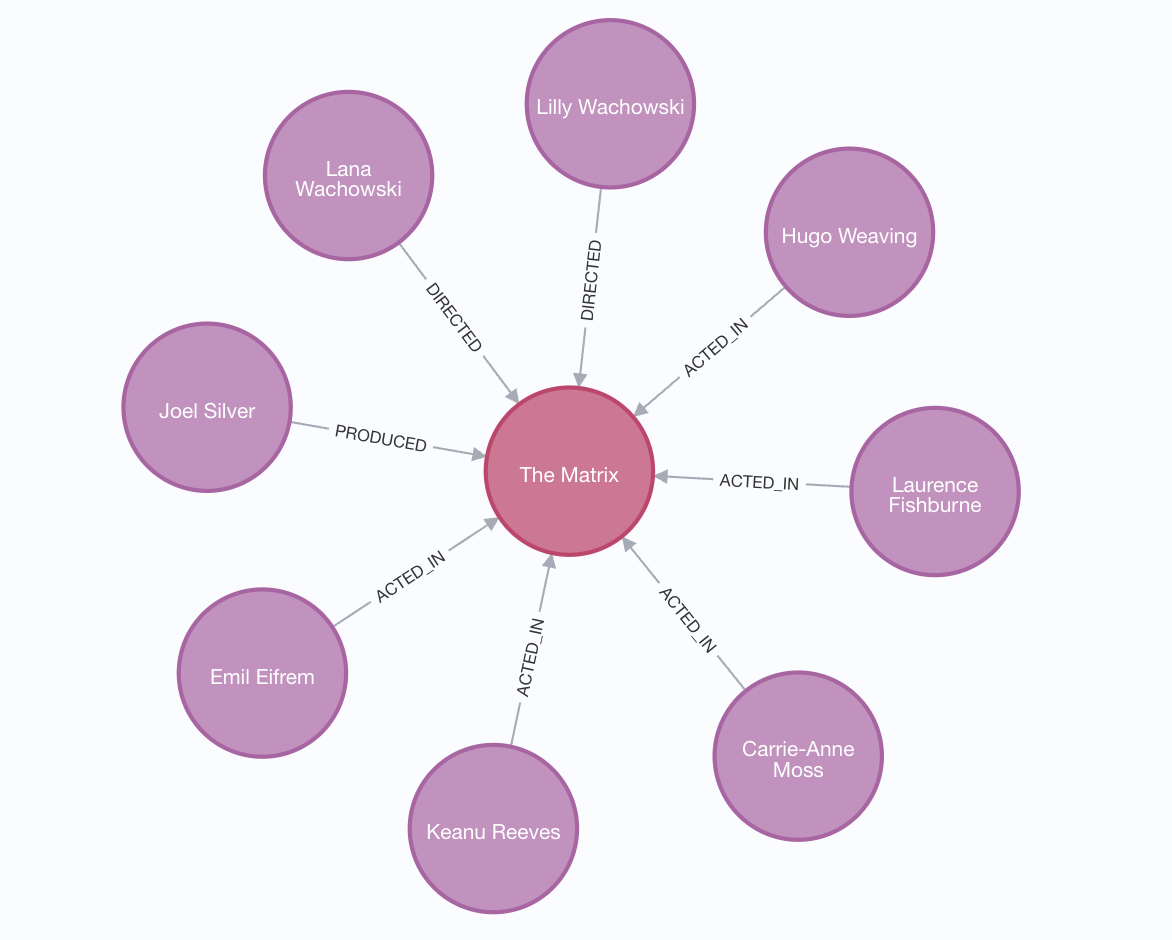
首先创建一个电影节点,节点上有三个属性,分别代表电影标题、发布时间、宣传词。
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
再创建人物节点,节点有两个属性,名字和出生日期。
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
然后创建演员、导演关系。
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix)
其中使用到了箭头运算符,如:(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),代表创建一个演员参演电影的关系,演员Keanu以角色roles:['Neo']参演ACTED_IN到电影中。 (LillyW)-[:DIRECTED]->(TheMatrix)表示导演与电影的关系。执行完毕后可以看到如下所示:
2.3.1 检索节点
查找人员
-
查找名为Tom Hanks的人物
MATCH (tom {name:"Tom Hanks"}) RETURN tom -
查找名为Cloud Atlas的电影
MATCH (cloudAtlas {name:"Cloud Atlas"}) RETURN tom -
随机查找10个人物的人名
MATCH (people:Person) RETURN people.name LIMIT 10 -
查找多个电影,1990-2000发行的电影的名称
MATCH (nineties:Movie) WHERE nineties.released > 1990 AND nineties.released < 2000 RETURN nineties.title
2.3.2 查询关系
-
查找Tom Hanks参演过的电影的名称
MATCH (tom:Person {name:"Tom Hanks"}) - [:ACTED_IN] -> (tomHanksMovies) RETURN tom,tomHanksMovies -
查询谁导演了电影“Cloud Atlas”
MATCH (cloudAtlas {title:"Cloud Atlas"}) <- [:DIRECTED] - (directors) RETURN directors.name
首先匹配属性{title:"Cloud Atlas"}的节点,然后匹配此节点具有关系 [:DIRECTED] 并且是被某节点指向的节点,再返回name属性。 -
查找与Tom Hanks同出演过电影的人
MATCH (tom:Person {name:"Tom Hanks"}) - [:ACTED_IN] -> (tomHanksMovies) <- [:ACTED_IN] - (coActors) RETURN coActors.name
首先匹配节点类型为Person,属性为tom hanks的节点,然后匹配此节点通过 [:ACTED_IN] 关系指向的节点,并且同时匹配该节点的 [:ACTED_IN] 关系节点。 -
查询与电影“Cloud Atlas”相关的所有人
MATCH (people:Person) - [relatedTo] - (:Movie {title: "Cloud Atlas"}) RETURN people.name, Type(relatedTo),relatedTo
首先匹配节点类型为Person的节点,然后匹配节点类型为Movie、节点属性为{title: "Cloud Atlas"}的节点,最好匹配他们两者之间存在某种关系,最后返回。