RocketMq技术内幕笔记(三)
4 消息存储
4.1 存储概要设计
RocketMQ主要存储的文件包括Comitlog文件、ConsumeQueue文件、IndexFile文
件。
RocketMQ将所有主题的消息存储在同一个文件中,确保消息发送时顺序写文件。为了提高消息消费的效率, RocketMQ 引入了 ConsumeQueue 消息队列 文件,每个消息主题包含多个消息消费队列,每一个消息队列有一个消息文件 - IndexFile索引文件,其主要设计理念就是为了加速消息的检索性能,根据消息的属性快速从 Commitlog 文件中检索消息。
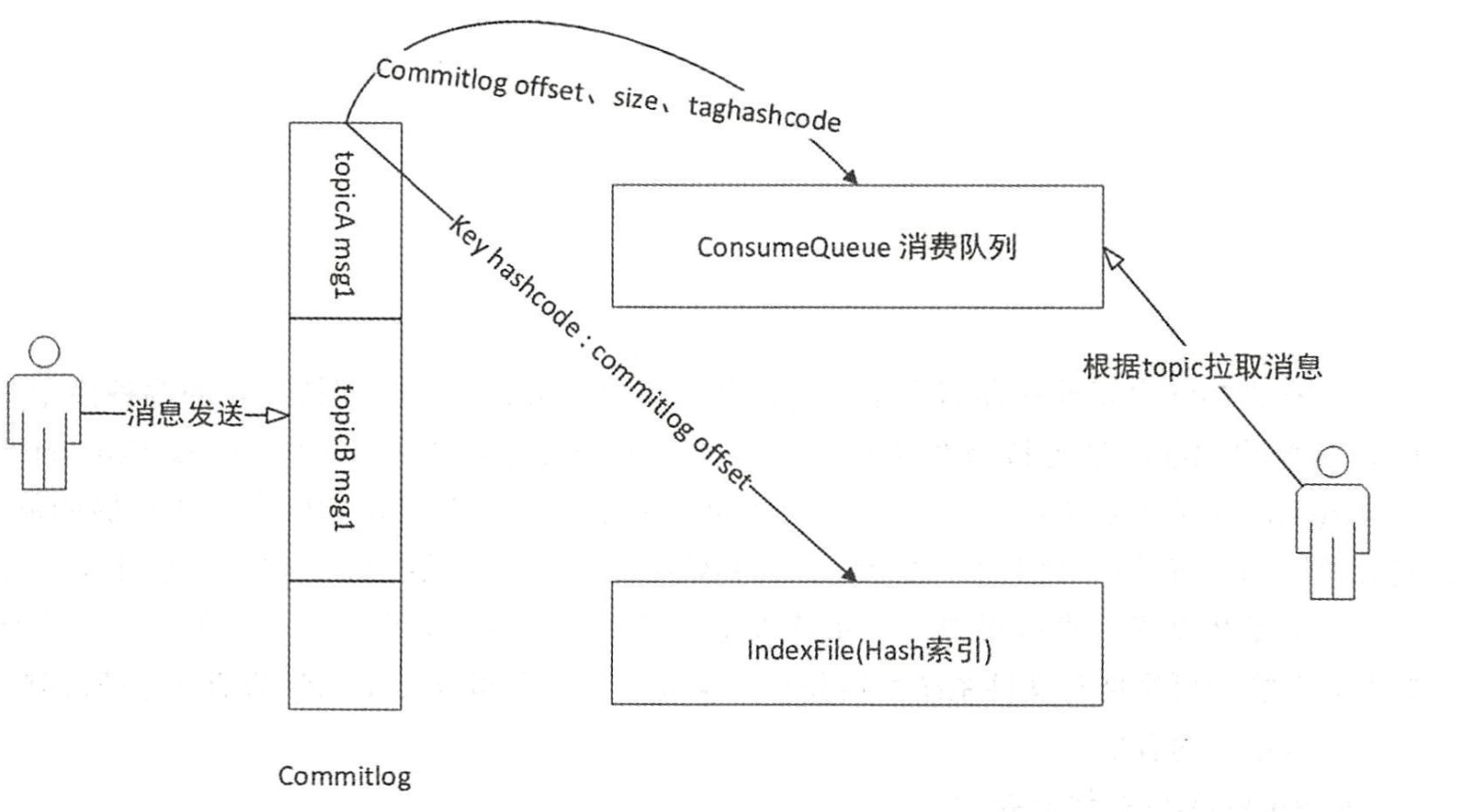
1 ) CommitLog:消息存储文件,所有消息主题的消息都存储在 CommitLog 文件中 。
2 ) ConsumeQueue :消息消费队列,消息到达CommitLog文件后,将异步转发到消息消费队列,供消息消费者消费 。
3 ) IndexFile:消息索引文件,主要存储消息 Key 与 Offset 的对应关系 。
4 )事务状态服务 : 存储每条消息的事务状态 。
5 )定时消息服务:每一个延迟级别对应一个消息消费队列,存储延迟队列的消息拉取
进度。
4.2 初识消息存储
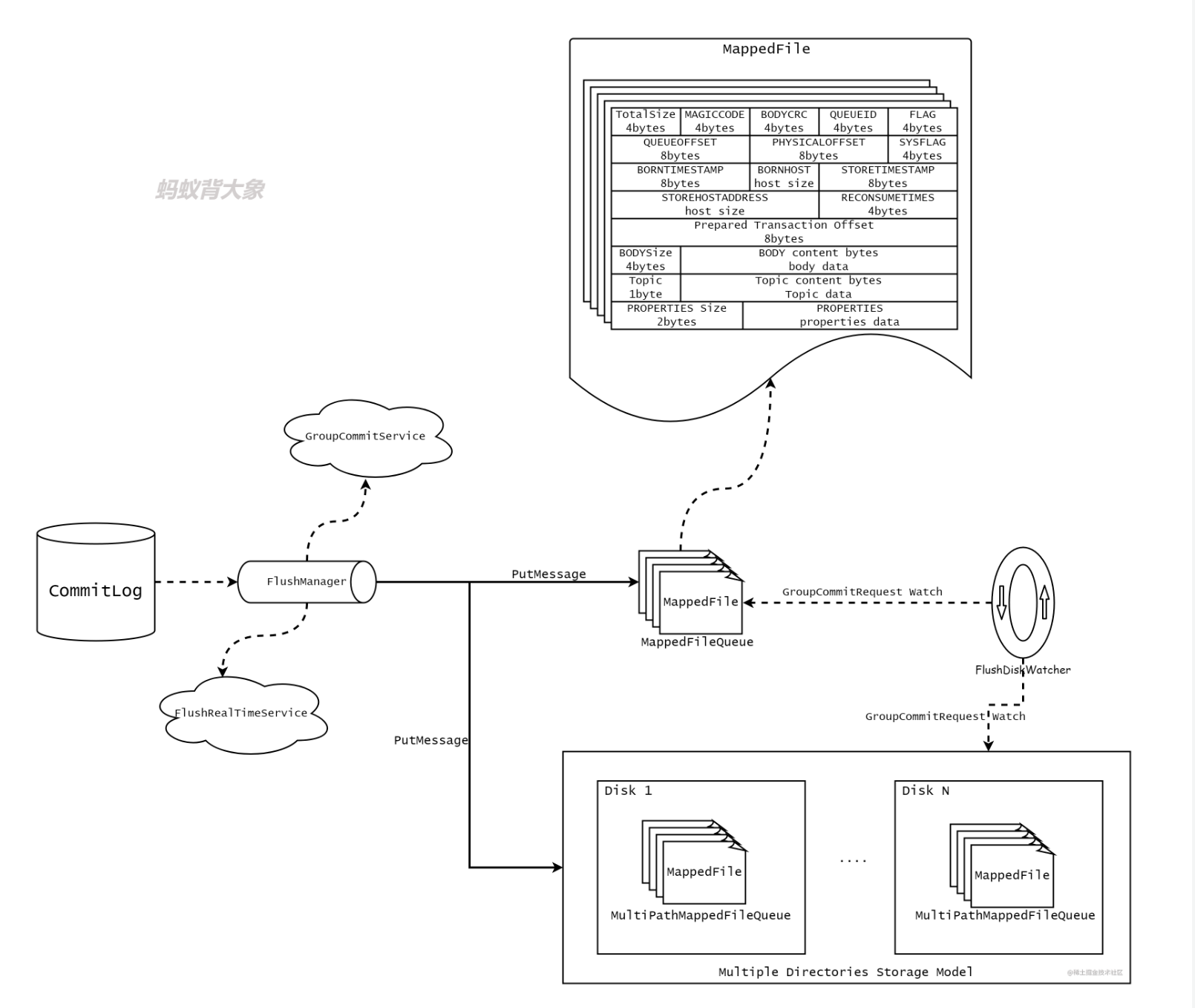
- CommitLog 主要由几部分组成:
MappedFileQueue: 主要用来操作相关数据存储文件。将一系列的MappedFile抽象成一个队列。
FlushManager: 数据落地磁盘的管理,主要分为两类:实时数据刷盘(FlushRealTimeService),以及异步刷盘(GroupCommitService)
FlushDiskWatcher: 刷盘观察者,处理队列中的刷盘请求,对于规定时间内没有刷盘成功的进行处理。
- MappedFileQueue
MappedFileQueue 是对数据存储文件的一个抽象,将多个数据文件抽象成为一个文件队列。通过这个文件队列对文件进行操作操作。同时保存一些 CommitLog 的属性。
- MappedFile
MappedFile 是对文件的抽象,包含了对RocketMQ数据文件的整个操作。例如获取文件名称、文件大小、判断文件是否可用、是否已经满了等等的操作。
单个数据文件默认是 1G 。由于只用了一个字节保存Topic的长度所以Topic的最大长度是127字符。
消息存储实现类: org.apache.rocketmq.store.DefaultMessageStore。
DefaultMessageStore的核心属性
//消息存储配置属性
private final MessageStoreConfig messageStoreConfig;
//CommitLog 文件的存储实现类
private final CommitLog commitLog;
//消息队列存储
private final ConsumeQueueStore consumeQueueStore;
//消息队列文件 ConsumeQueue刷盘线程。
private final FlushConsumeQueueService flushConsumeQueueService;
//清除 CommitLog 文件服务
private final CleanCommitLogService cleanCommitLogService;
//清除 ConsumeQueue 文件服务
private final CleanConsumeQueueService cleanConsumeQueueService;
private final CorrectLogicOffsetService correctLogicOffsetService;
//索引文件实现类
private final IndexService indexService;
//MappedFile 分配服务
private final AllocateMappedFileService allocateMappedFileService;
//CommitLog消息分发,根据 CommitLog文件构建 ConsumeQueue、 IndexFile 文件 。
private ReputMessageService reputMessageService;
//存储 HA 机制
private HAService haService;
//消息堆内存缓存
private final StoreStatsService storeStatsService;
private final TransientStorePool transientStorePool;
private final RunningFlags runningFlags = new RunningFlags();
private final SystemClock systemClock = new SystemClock();
private final ScheduledExecutorService scheduledExecutorService;
private final BrokerStatsManager brokerStatsManager;
//消息拉取长轮询模式消息达到监听器
private final MessageArrivingListener messageArrivingListener;
//Broker配置属性
private final BrokerConfig brokerConfig;
private volatile boolean shutdown = true;
//文件刷盘检测点
private StoreCheckpoint storeCheckpoint;
private TimerMessageStore timerMessageStore;
private AtomicLong printTimes = new AtomicLong(0);
//CommitLog 文件转发请求
private final LinkedList<CommitLogDispatcher> dispatcherList;
4.3 消息发送存储流程
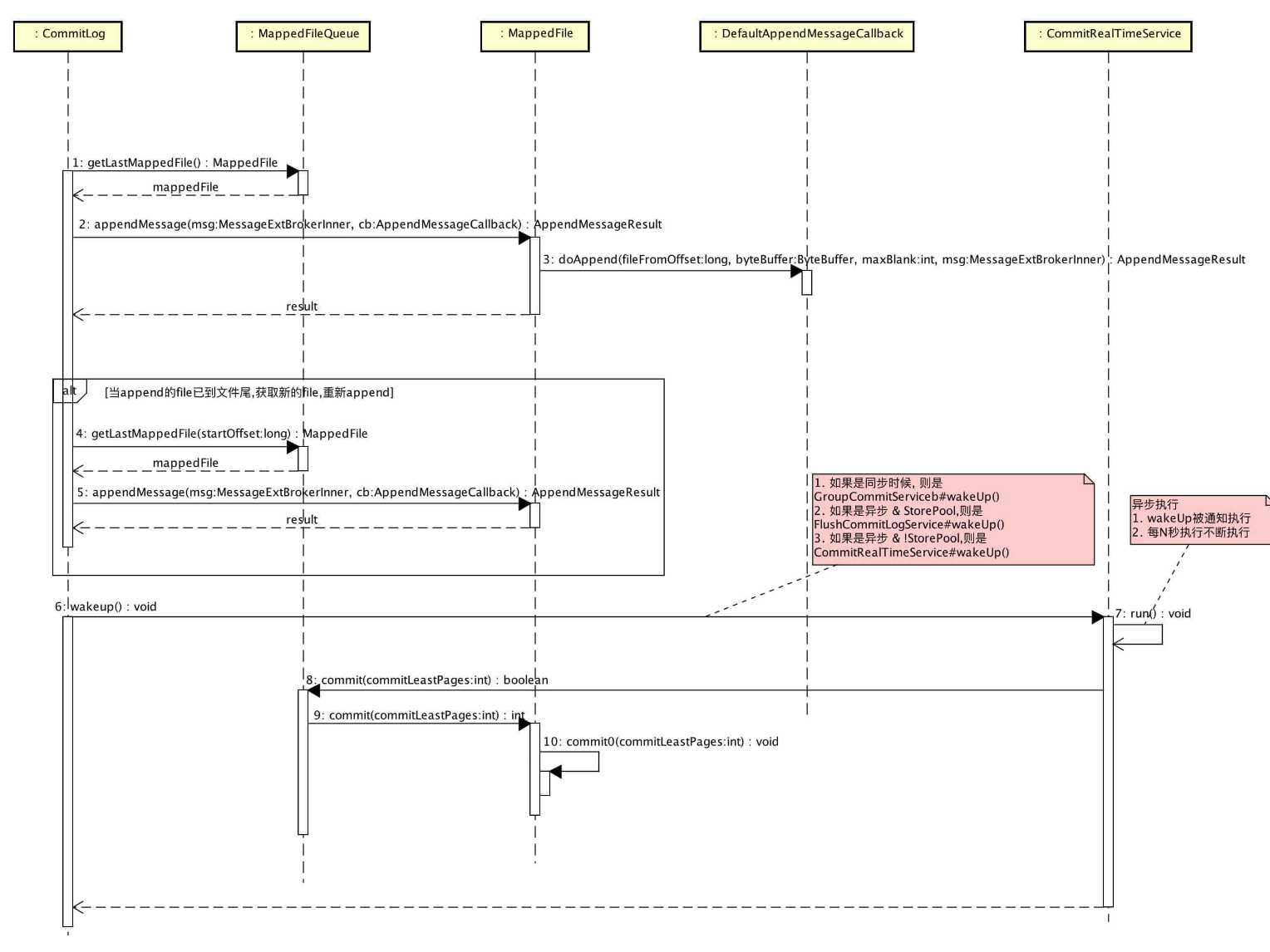
消息存储入口: org.apache.rocketmq.store.DefaultMessageStore#putMessage。
Step 1:如果当前Broker停止工作或 Broker为SLAVE角色或当前Rocket不支持写入则拒绝消息写入;如果消息主题长度超过256个字符、消息属性长度超过65536个字符将拒绝该消息写人。
Step 2:如果消息的延迟级别大于0,将消息的原主题名称与原消息队列 ID 存入消息属性中,用延迟消息主题SCHEDULE_TOPIC、消息队列 ID 更新原先消息的主题与队列。
Step 3:获取当前可以写入的 Commitlog文件
MappedFile unlockMappedFile = null;
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
Commitlog文件存储目录为 {ROCKET_HOME}/store/commitlog文件夹,而MappedFile则对应该文件夹下一个个的文件。
Step 4:在写入Commitlog之前,先申请putMessageLock,也就是将消息存储到Commitlog文件中是串行的 。
putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
**Step 5 **:设置消息的存储时间,如果mappedFile为空,表明$ {ROCKET_HOME}/store/Commitlog目录下不存在任何文件,说明本次消息是第一次消息发送,用偏移量0创建第一个commit文件,文件为 00000000000000000000,如果文件创建失败,抛出 CREATE MAPEDFILE FAILED,很有可能是磁盘空间不足或权限不够。
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = this.mappedFileQueue.getLastMappedFile(0); // Mark: NewFile may be cause noise
}
if (null == mappedFile) {
log.error("create mapped file1 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());
beginTimeInLock = 0;
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.CREATE_MAPPED_FILE_FAILED, null));
}
Step 6 :将消息追加到 MappedFile 中。 首先先获取 MappedFile 当前写指针,如果currentPos大于或等于文件大小则表明文件已写满,抛出 AppendMessageStatus.UNKNOWN_ ERROR。 如果 currentPos小于文件大小,通过 slice()方法创建一个与 MappedFile 的共享内存区,并设置position 为当前指针。
public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb,
PutMessageContext putMessageContext) {
assert messageExt != null;
assert cb != null;
int currentPos = WROTE_POSITION_UPDATER.get(this);
if (currentPos < this.fileSize) {
ByteBuffer byteBuffer = appendMessageBuffer().slice();
byteBuffer.position(currentPos);
AppendMessageResult result;
if (messageExt instanceof MessageExtBatch && !((MessageExtBatch) messageExt).isInnerBatch()) {
// traditional batch message
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos,
(MessageExtBatch) messageExt, putMessageContext);
} else if (messageExt instanceof MessageExtBrokerInner) {
// traditional single message or newly introduced inner-batch message
result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos,
(MessageExtBrokerInner) messageExt, putMessageContext);
} else {
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
WROTE_POSITION_UPDATER.addAndGet(this, result.getWroteBytes());
this.storeTimestamp = result.getStoreTimestamp();
return result;
}
log.error("MappedFile.appendMessage return null, wrotePosition: {} fileSize: {}", currentPos, this.fileSize);
return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);
}
Step 7:创建全局唯一消息 ID,消息ID有16字节。前4字节为IP,中间4字节为端口号,最后8字节为消息偏移量。
long wroteOffset = fileFromOffset + byteBuffer.position();
Supplier<String> msgIdSupplier = () -> {
int sysflag = msgInner.getSysFlag();
int msgIdLen = (sysflag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 4 + 4 + 8 : 16 + 4 + 8;
ByteBuffer msgIdBuffer = ByteBuffer.allocate(msgIdLen);
MessageExt.socketAddress2ByteBuffer(msgInner.getStoreHost(), msgIdBuffer);
msgIdBuffer.clear();//because socketAddress2ByteBuffer flip the buffer
msgIdBuffer.putLong(msgIdLen - 8, wroteOffset);
return UtilAll.bytes2string(msgIdBuffer.array());
};
可以通过 UtilAll.bytes2string方法将 msgld 字节数组转换成字符串,通过 Uti1All.string2bytes 方法将msgld字符串还原成16个字节的字节数组,从而根据提取消息偏移量,可以快速通过msgld找到消息内容。
Step 8 : 获取该消息在消息队列的偏移量。CommitLog中保存了当前所有消息队列的当前待写入偏移量。
Step 9:根据消息、体的长度、主题的长度、属性的长度结合消息存储格式计算消息的总长度。
Step l0 :如果消息长度+END_FILE_MIN_BLANK_LENGTH大于CommitLog文件的空闲空间,则返回 AppendMessageStatus.END_OF_FILE, Broker会重新创建一个新的 CommitLog文件来存储该消息。 从这里可以看出,每个CommitLog文件最少会空闲 8个字 节,高4字节存储当前文件剩余空间,低4字节存储魔数 : CommitLog.BLANK MAGIC CODE 。
if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) {
this.msgStoreItemMemory.clear();
// 1 TOTALSIZE
this.msgStoreItemMemory.putInt(maxBlank);
// 2 MAGICCODE
this.msgStoreItemMemory.putInt(CommitLog.BLANK_MAGIC_CODE);
// 3 The remaining space may be any value
// Here the length of the specially set maxBlank
final long beginTimeMills = CommitLog.this.defaultMessageStore.now();
byteBuffer.put(this.msgStoreItemMemory.array(), 0, 8);
return new AppendMessageResult(AppendMessageStatus.END_OF_FILE, wroteOffset,
maxBlank, /* only wrote 8 bytes, but declare wrote maxBlank for compute write position */
msgIdSupplier, msgInner.getStoreTimestamp(),
queueOffset, CommitLog.this.defaultMessageStore.now() - beginTimeMills);
}
Step 11 :将消息内容存储到ByteBuffer中,然后创建AppendMessageResult。 这里只是将消息存储在 MappedFile对应的内存映射Buffer中,并没有刷写到磁盘。
final long beginTimeMills = CommitLog.this.defaultMessageStore.now();
CommitLog.this.getMessageStore().getPerfCounter().startTick("WRITE_MEMORY_TIME_MS");
// Write messages to the queue buffer
byteBuffer.put(preEncodeBuffer);
CommitLog.this.getMessageStore().getPerfCounter().endTick("WRITE_MEMORY_TIME_MS");
msgInner.setEncodedBuff(null);
return new AppendMessageResult(AppendMessageStatus.PUT_OK, wroteOffset, msgLen, msgIdSupplier,msgInner.getStoreTimestamp(), queueOffset, CommitLog.this.defaultMessageStore.now() - beginTimeMills, messageNum);
AppendMessageResult核心属性
public class AppendMessageResult {
//消息追加结果 PUT_OK :追加成功;END_OF_FILE :超过文件大小;MESSAGE SIZE EXCEEDED :消息长度超过最大允许长度: PROPERTIES_SIZE_EXCEEDED :消息、属性超过最大允许长度; UNKNOWN ERROR :未知异常 。
private AppendMessageStatus status;
// 消息的物理偏移量
private long wroteOffset;
// 消息的大小
private int wroteBytes;
// 消息 ID
private String msgId;
private Supplier<String> msgIdSupplier;
// 消息存储时间戳
private long storeTimestamp;
// 消息消费队列逻辑偏移量,类似于数组下标
private long logicsOffset;
private long pagecacheRT = 0;
//消息条数,批量消息发送时消息条数
private int msgNum = 1;
}
Step 12:更新消息队列逻辑偏移量 。
Step 13:处理完消息追加逻辑后将释放 putMessageLock锁。
Step 14 : DefaultAppendMessageCallback#doAppend 只是将消息追加在内存中, 需要根据是同步刷盘还是异步刷盘方式,将内存中的数据持久化到磁盘,然后执行 HA 主从同步复制。
4.4 存储文件组织与内存映射
RocketMQ通过使用内存映射文件来提高IO访问性能,无论是CommitLog、 ConsumeQueue还是 IndexFile,单个文件都被设计为固定长度,如果一个文件写满以后再创建一个新文件,文件名就为该文件第 一条消息对应的全局物理偏移量。
4.4.1 MappedFileQueue 映射文件队列
MappedFileQueu巳是 MappedFile 的管理容器, Mapp巳dFileQueue是对存储目录的封装,例如 CommitLog文件的存储路径${ROCKET_HOME}/store/commitlog/,该目录下会存在多个内存映射文件(MappedFile)。
public class MappedFileQueue implements Swappable {
//存储目录
protected final String storePath;
//单个文件的存储大小
protected final int mappedFileSize;
//MappedFile 文件集合
protected final CopyOnWriteArrayList<MappedFile> mappedFiles = new CopyOnWriteArrayList<MappedFile>();
//创建 MappedFile服务类
protected final AllocateMappedFileService allocateMappedFileService;
//当前刷盘指针,表示该指针之前的所有数据全部持久化到磁盘
protected long flushedWhere = 0;
//当前数据提交指针,内存中ByteBuffer当前的写指针,该值大于等于flushedWhere
protected long committedWhere = 0;
protected volatile long storeTimestamp = 0;
}
查找 MappedFile
/**
* 查找 MappedFile
* @param timestamp
* @return
*/
public MappedFile getMappedFileByTime(final long timestamp) {
Object[] mfs = this.copyMappedFiles(0);
if (null == mfs)
return null;
for (int i = 0; i < mfs.length; i++) {
MappedFile mappedFile = (MappedFile) mfs[i];
if (mappedFile.getLastModifiedTimestamp() >= timestamp) {
return mappedFile;
}
}
return (MappedFile) mfs[mfs.length - 1];
}
根据消息存储时间戳来查找 MappdFile。从MappedFile 列表中第一个文件开始查找,找到第一个最后一次更新时间大于待查找时间戳的文件,如果不存在,则返回最后一个MappedFile文件。
RocketMQ 采取定时删除存储文件的策略,也就是说在存储文件中, 第一个文件不一定是 00000000000000000000,因为该文件在某一时刻会被删除,故根据offset定位MappedFile的算法为
(int) ((offset / this.mappedFileSize) - (firstMappedFile.getFileFromOffset() / this.mappedFileSize));
MappedFileQueue#findMappedFileByOffset
public MappedFile findMappedFileByOffset(final long offset, final boolean returnFirstOnNotFound) {
try {
MappedFile firstMappedFile = this.getFirstMappedFile();
MappedFile lastMappedFile = this.getLastMappedFile();
if (firstMappedFile != null && lastMappedFile != null) {
if (offset < firstMappedFile.getFileFromOffset() || offset >= lastMappedFile.getFileFromOffset() + this.mappedFileSize) {
LOG_ERROR.warn("Offset not matched. Request offset: {}, firstOffset: {}, lastOffset: {}, mappedFileSize: {}, mappedFiles count: {}",
offset,
firstMappedFile.getFileFromOffset(),
lastMappedFile.getFileFromOffset() + this.mappedFileSize,
this.mappedFileSize,
this.mappedFiles.size());
} else {
int index = (int) ((offset / this.mappedFileSize) - (firstMappedFile.getFileFromOffset() / this.mappedFileSize));
MappedFile targetFile = null;
try {
targetFile = this.mappedFiles.get(index);
} catch (Exception ignored) {
}
if (targetFile != null && offset >= targetFile.getFileFromOffset()
&& offset < targetFile.getFileFromOffset() + this.mappedFileSize) {
return targetFile;
}
for (MappedFile tmpMappedFile : this.mappedFiles) {
if (offset >= tmpMappedFile.getFileFromOffset()
&& offset < tmpMappedFile.getFileFromOffset() + this.mappedFileSize) {
return tmpMappedFile;
}
}
}
if (returnFirstOnNotFound) {
return firstMappedFile;
}
}
} catch (Exception e) {
log.error("findMappedFileByOffset Exception", e);
}
return null;
}
获取存储文件最小偏移量,从这里也可以看出,并不是直接返回0,而是返回MappedFile的 getFileFormOffset()。
public long getMinOffset() {
if (!this.mappedFiles.isEmpty()) {
try {
return this.mappedFiles.get(0).getFileFromOffset();
} catch (IndexOutOfBoundsException e) {
//continue;
} catch (Exception e) {
log.error("getMinOffset has exception.", e);
}
}
return -1;
}
获取存储文件的最大偏移量。 返回最后一个Mapp巳dFile文件的fileFromOffset加上MappedFile 文件当前的读指针。
public long getMaxOffset() {
MappedFile mappedFile = getLastMappedFile();
if (mappedFile != null) {
return mappedFile.getFileFromOffset() + mappedFile.getReadPosition();
}
return 0;
}
返回存储文件当前的写指针。 返回最后一个文件的 fileFromOffset加上当前写指针位置。
public long getMaxWrotePosition() {
MappedFile mappedFile = getLastMappedFile();
if (mappedFile != null) {
return mappedFile.getFileFromOffset() + mappedFile.getWrotePosition();
}
return 0;
}
4.4.2 MappedFile 内存映射文件
MappedFile 是RocketMQ内存映射文件的具体实现。
public class DefaultMappedFile extends AbstractMappedFile {
//操作系统每页大小,默认4k
public static final int OS_PAGE_SIZE = 1024 * 4;
protected static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
//当前JVM实例中Mapped File虚拟内存
protected static final AtomicLong TOTAL_MAPPED_VIRTUAL_MEMORY = new AtomicLong(0);
//当前JVM实例中MappedFile对象个数
protected static final AtomicInteger TOTAL_MAPPED_FILES = new AtomicInteger(0);
protected static final AtomicIntegerFieldUpdater<DefaultMappedFile> WROTE_POSITION_UPDATER;
protected static final AtomicIntegerFieldUpdater<DefaultMappedFile> COMMITTED_POSITION_UPDATER;
protected static final AtomicIntegerFieldUpdater<DefaultMappedFile> FLUSHED_POSITION_UPDATER;
//当前该文件的写指针,从0开始
protected volatile int wrotePosition;
//当前文件的提交指针,如果开启transientStorePoolEnable 则数据会存储在TransientStorePool中,然后提交到内存映射ByteBuffer中,再刷写到磁盘。
protected volatile int committedPosition;
//刷写到磁盘指针,该指针之前的数据持久化到磁盘中
protected volatile int flushedPosition;
//文件大小
protected int fileSize;
//文件通道
protected FileChannel fileChannel;
/**
* Message will put to here first, and then reput to FileChannel if writeBuffer is not null.
*/
//堆内存ByteBuffer,如果不为空,数据首先将存储在该Buffer中,然后提交到MappedFile对应的内存映射文件Buffer。transientStorePoolEnable为true时不为空。
protected ByteBuffer writeBuffer = null;
//堆内存池, transientStorePoolEnable为true时启用。
protected TransientStorePool transientStorePool = null;
//文件名称
protected String fileName;
//该文件的初始偏移量
protected long fileFromOffset;
//物理文件
protected File file;
//物理文件对应的内存映射 Buffer
protected MappedByteBuffer mappedByteBuffer;
//文件最后一次 内容写入时间
protected volatile long storeTimestamp = 0;
//是否是MappedFileQueue队列中第一个文件
protected boolean firstCreateInQueue = false;
private long lastFlushTime = -1L;
protected MappedByteBuffer mappedByteBufferWaitToClean = null;
protected long swapMapTime = 0L;
protected long mappedByteBufferAccessCountSinceLastSwap = 0L;
}
1. MappedFile初始化
根据是否开启 transientStorePoo!Enable 在两种初始化情况 transientStorePoolEnable
true表示内容先存储在堆外内存,然后通过 Commit 线程将数据提交到内存映射 uffer
中,再通过 Flush 线程将内存映射 Buffer中的数据持化到磁盘中。
>初始化
private void init(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
//初始化 fileFromOffset 为文件名,也就是文件名代表该文件的起始偏移量
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
UtilAll.ensureDirOK(this.file.getParent());
try {
//创建读写文件通道,并将文件内容使用 NIO 的内存映射 Buffer将文件映 射到内存中。
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("Failed to create file " + this.fileName, e);
throw e;
} catch (IOException e) {
log.error("Failed to map file " + this.fileName, e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
如果transientstorePooIEnabIe 为 true,则初始化 MappedFile 的 writeBuffer。
初始化
@Override
public void init(final String fileName, final int fileSize,
final TransientStorePool transientStorePool) throws IOException {
init(fileName, fileSize);
this.writeBuffer = transientStorePool.borrowBuffer();
this.transientStorePool = transientStorePool;
}
2. MappedFile提交(commit)
内存映射文件的提交动作由 MappedFile 的commit方法实现。
Commit代码
@Override
public int commit(final int commitLeastPages) {
if (writeBuffer == null) {
//no need to commit data to file channel, so just regard wrotePosition as committedPosition.
//writeBuffer如果为空,直接返回 wrotePosition指针
return WROTE_POSITION_UPDATER.get(this);
}
//判断是否达到最小提交页数,不满则不执行本次提交操作,待下次提交
if (this.isAbleToCommit(commitLeastPages)) {
if (this.hold()) {
//具体提交
commit0();
this.release();
} else {
log.warn("in commit, hold failed, commit offset = " + COMMITTED_POSITION_UPDATER.get(this));
}
}
// All dirty data has been committed to FileChannel.
if (writeBuffer != null && this.transientStorePool != null && this.fileSize == COMMITTED_POSITION_UPDATER.get(this)) {
this.transientStorePool.returnBuffer(writeBuffer);
this.writeBuffer = null;
}
return COMMITTED_POSITION_UPDATER.get(this);
}
判断是否需要提交
protected boolean isAbleToCommit(final int commitLeastPages) {
int commit = COMMITTED_POSITION_UPDATER.get(this);
int write = WROTE_POSITION_UPDATER.get(this);
//如果文件满了
if (this.isFull()) {
return true;
}
//如果 commitLeastPages大于 0, 则比较 wrotePosition( 当前 writeBuffer 的写指针)与上 一次提交的指针(committedPosition)
// 的差值,除以 OS_PAGE_SIZE得到当前脏页的数量,如果大于 commitLeastPages则返回 true;
if (commitLeastPages > 0) {
return ((write / OS_PAGE_SIZE) - (commit / OS_PAGE_SIZE)) >= commitLeastPages;
}
// 如果 commitLeastPages 小 于 0 表示只要存在脏页就提交
return write > commit;
}
具体提交
protected void commit0() {
int writePos = WROTE_POSITION_UPDATER.get(this);
int lastCommittedPosition = COMMITTED_POSITION_UPDATER.get(this);
if (writePos - lastCommittedPosition > 0) {
try {
//创建 writeBuffer的共享缓存区
ByteBuffer byteBuffer = writeBuffer.slice();
//将新创建的 position 回 退到上一次提交的位置( lastCommittedPosition)
byteBuffer.position(lastCommittedPosition);
//设置 limit为 wrotePosition (当前最大有效数据指针)
byteBuffer.limit(writePos);
//更新committedPosition指针为wrotePosition
this.fileChannel.position(lastCommittedPosition);
//把lastCommittedPosition到wrotePosition的数据复制 (写入)到FileChannel中
this.fileChannel.write(byteBuffer);
COMMITTED_POSITION_UPDATER.set(this, writePos);
} catch (Throwable e) {
log.error("Error occurred when commit data to FileChannel.", e);
}
}
}
commit的作用就是将MappedFile# writeBuffer 中的数据提交到文件通道 FileChannel 中。
ByteBuffer 使用技巧 : slice() 方法创建 一 个共享缓存区 ,与原先的 ByteBuffer 共享内存但维护一套独立的指针 (position、 mark、 limit)。
3. MappedFile刷盘(flush)
刷盘指的是将内存中的数据刷写到磁盘,永久存储在磁盘中,其具体实现由MappedFile的flush方法实现。
flush方法
@Override
public int flush(final int flushLeastPages) {
if (this.isAbleToFlush(flushLeastPages)) {
if (this.hold()) {
//获取最大读指针
int value = getReadPosition();
try {
this.mappedByteBufferAccessCountSinceLastSwap++;
//We only append data to fileChannel or mappedByteBuffer, never both.
if (writeBuffer != null || this.fileChannel.position() != 0) {
this.fileChannel.force(false);
} else {
this.mappedByteBuffer.force();
}
this.lastFlushTime = System.currentTimeMillis();
} catch (Throwable e) {
log.error("Error occurred when force data to disk.", e);
}
FLUSHED_POSITION_UPDATER.set(this, value);
this.release();
} else {
log.warn("in flush, hold failed, flush offset = " + FLUSHED_POSITION_UPDATER.get(this));
FLUSHED_POSITION_UPDATER.set(this, getReadPosition());
}
}
return this.getFlushedPosition();
}
刷写磁盘,直接调用mappedByteBuffer或fileChannel的force方法将内存中的数据持久化到磁盘,那么 flushedPosition应该等于MappedByteBuffer中的写指针;如果writeBuffer不为空,flushedPosition应等于上一次commit指针;因为上一次提交的数据就是进入到MappedByteBuffer中的数据;如果 writeBuffer为空,数据是直接进入到MappedByteBuffer, wrotePosition代表的是 MappedByteBuffer中的指针,故设置flushedPosition为wrotePosition。
4. 获取 MappedFile 最大读指针( getReadPosition)
获取最大读指针
public int getReadPosition() {
return this.writeBuffer == null ? WROTE_POSITION_UPDATER.get(this) : COMMITTED_POSITION_UPDATER.get(this);
}
获取当前文件最大的可读指针。如果writeBuffer为空,则直接返回当前的写指针;如果writeBuffer不为空, 则返回上一次提交的指针。只有提交了的数据(写入到 MappedByteBuffer或 FileChannel中的数据 )才是安全的数据。
MappedFile#selectMappedBuffer
public SelectMappedBufferResult selectMappedBuffer(int pos, int size) {
int readPosition = getReadPosition();
if ((pos + size) <= readPosition) {
if (this.hold()) {
this.mappedByteBufferAccessCountSinceLastSwap++;
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
byteBuffer.position(pos);
ByteBuffer byteBufferNew = byteBuffer.slice();
byteBufferNew.limit(size);
return new SelectMappedBufferResult(this.fileFromOffset + pos, byteBufferNew, size, this);
} else {
log.warn("matched, but hold failed, request pos: " + pos + ", fileFromOffset: "
+ this.fileFromOffset);
}
} else {
log.warn("selectMappedBuffer request pos invalid, request pos: " + pos + ", size: " + size
+ ", fileFromOffset: " + this.fileFromOffset);
}
return null;
}
查找 pos 到当前最大可读之间的数据,由于在整个写入期间都未曾改变 MappedByteBuffer的指针 ,所以mappedByteBuffer.slice()方法返回的共享缓存区空间为整个MappedFile,然后通过设置 byteBuffer的position为待查找的值,读取字节为当前可读字节长度,最终返回的 ByteBuffer 的 limit (可读 最大长度)为 size。整个共享缓存区的容量为(MappedFile#fileSize-pos),故在操作SelectMappedBufferResult不能对包含在里面的ByteBuffer调用flip方法。
操作ByteBuffer 时如果使用了slice()方法,对其ByteBuffer进行读取时一般手动指定position与limit 指针,而不是调用flip方法来切换读写状态。
5 . MappedFile 销毁( destory)
MappedFile文件销毁的实现方法为public boolean destroy(final long intervalForcibly), intervalForcibly表示拒绝被销毁的最大存活时间。
Step 1:关闭MappedFile
destroy -> shutdown()
public void shutdown(final long intervalForcibly) {
if (this.available) {
//初次调用时 this.available 为 true,设置 available 为 false
this.available = false;
//设置初次关闭的时间戳( firstShutdownTimestamp)为当前时间戳
this.firstShutdownTimestamp = System.currentTimeMillis();
//然后调用 release()方法 尝试释放资源,
this.release();
} else if (this.getRefCount() > 0) {
//引用次数大于0,对比当前时间与 firstShutdownTimestamp,如果已经超过了其最大拒绝存活期,每执行一次,将引用数减少 1000,直到引用数小于0
if ((System.currentTimeMillis() - this.firstShutdownTimestamp) >= intervalForcibly) {
this.refCount.set(-1000 - this.getRefCount());
this.release();
}
}
}
Step2 : 判断是否清理完成
判断是否清理完成
public boolean isCleanupOver() {
//引用次数小于等于0并且 cleanupOver为 true, cleanupOver为true的触发条件是release成功将MappedByteBuffer资源释放。
return this.refCount.get() <= 0 && this.cleanupOver;
}
Step3: 关闭文件通道, 删除物理文件。
long lastModified = getLastModifiedTimestamp();
this.fileChannel.close();
log.info("close file channel " + this.fileName + " OK");
long beginTime = System.currentTimeMillis();
boolean result = this.file.delete();
在整 MappedFile销毁过程,首先需要释放资源,释放资源的前提条件是该 MappedFile 的引用小于等于 0,接下来重点看一下release方法的实现原理。
public void release() {
long value = this.refCount.decrementAndGet();
if (value > 0)
return;
synchronized (this) {
this.cleanupOver = this.cleanup(value);
}
}
如果引用数小于等于0,则执行 cleanup 方法
cleanup()
public boolean cleanup(final long currentRef) {
if (this.isAvailable()) {
//available为true,表示MappedFile当前可用,无须清理
log.error("this file[REF:" + currentRef + "] " + this.fileName
+ " have not shutdown, stop unmapping.");
return false;
}
if (this.isCleanupOver()) {
//资源已经被清除,返回true
log.error("this file[REF:" + currentRef + "] " + this.fileName
+ " have cleanup, do not do it again.");
return true;
}
//如果是堆外内存,调用堆外内存的cleanup方法清除
UtilAll.cleanBuffer(this.mappedByteBuffer);
UtilAll.cleanBuffer(this.mappedByteBufferWaitToClean);
this.mappedByteBufferWaitToClean = null;
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(this.fileSize * (-1));
TOTAL_MAPPED_FILES.decrementAndGet();
log.info("unmap file[REF:" + currentRef + "] " + this.fileName + " OK");
return true;
}
4.4.3 TransientStorePool
TransientStorePool: 短暂的存储池。 RocketMQ单独创建一个MappedByteBuffer内存缓存池,用来临 时存储数据,数据先写人该内存映射中,然后由commit线程定时将数据从该内存复制到与目的物理文件对应的内存映射中。主要作用提供一种内存锁定,将当前堆外内存一直锁定在内存中,避免被进程将内存交换到磁盘。
核心属性
public class TransientStorePool {
//avaliableBuffers个数,可通过在broker中配置文件中设置 transient-StorePoolSize,默认为5。
private final int poolSize;
//每个 ByteBuffer大小, 默认为mappedFileSizeCommitLog,表明TransientStorePool为commitlog文件服务
private final int fileSize;
//ByteBuffer容器,双端队列
private final Deque<ByteBuffer> availableBuffers;
private final MessageStoreConfig storeConfig;
}
初始化
public void init() {
//创建 poolSize个堆外内存 , 并利用com.sun.jna.Library类库将该批内存锁定,避免被置换到交换区,提高存储性能
for (int i = 0; i < poolSize; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize);
final long address = ((DirectBuffer) byteBuffer).address();
Pointer pointer = new Pointer(address);
LibC.INSTANCE.mlock(pointer, new NativeLong(fileSize));
availableBuffers.offer(byteBuffer);
}
}
4.5 RocketMQ 存储文件
RocketMQ 存储路径为${ROCKET_HOME}/store
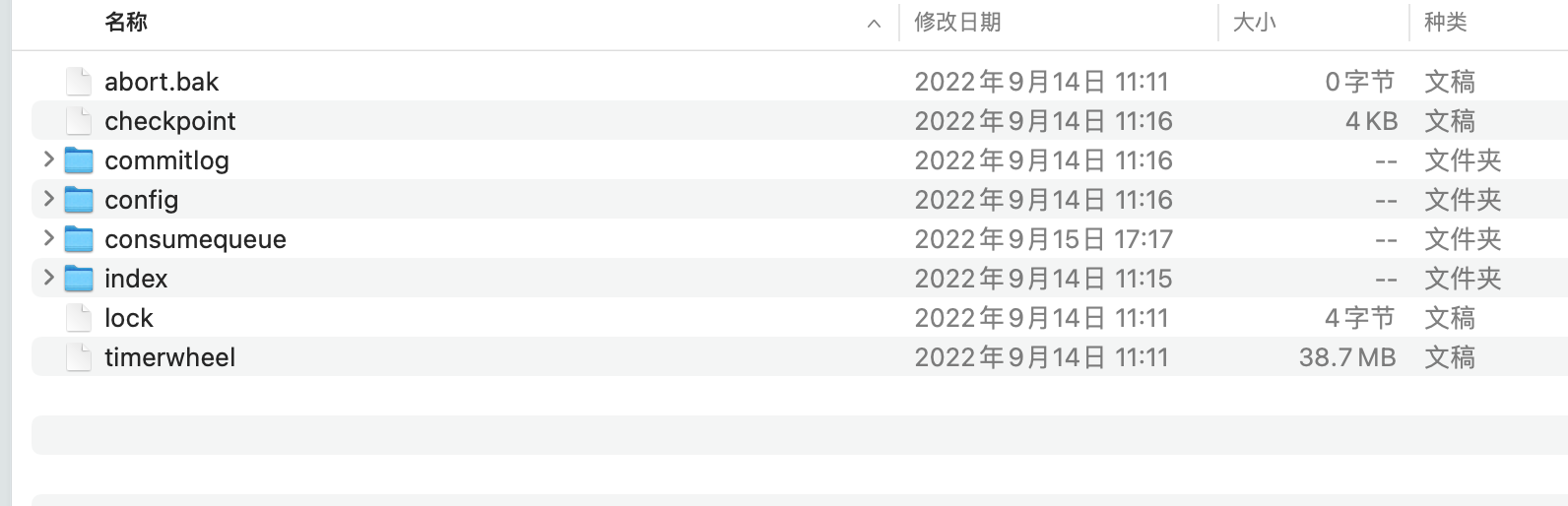
- commitlog:消息存储目录
- config:运行期间一些配置信息,主要包括下列信息
consumerFilter.json: 主题消息过滤信息
consumerOffset.json: 集群消费模式消息消费进度
delayOffset.json:延时消息队列拉取进度
subscriptionGroup.json: 消息消费组配置信息
topics.json: topic配置属性 - consumequ巳ue:消息消费队列存储目录
- index:消息索引文件存储目录。
- abort :如果存在 abort文件说明 Broker非正常关闭,该文件默认启动时创建,正常
退出之前删除 。 - checkpoint:文件检测点,存储 commitlog文件最后一次刷盘时间戳、 consumequeue
最后一次刷盘时间、 index 索引文件最后一次刷盘时间戳
4.5.1 Commitlog 文件
Commitlog 文件存储的逻辑视图如下所示,每条消息的前面4个字节存储该条消息的总长度。

分析消息的查找实现
Step 1:获取当前 Commitlog 目录最小偏移量 ,首先获取目录下的第一个文件,如果该文件可用, 则返回该文件的起始偏移量,否则返回下一个文件的起始偏移量。
获取最小偏移量
public long getMinOffset() {
MappedFile mappedFile = this.mappedFileQueue.getFirstMappedFile();
if (mappedFile != null) {
if (mappedFile.isAvailable()) {
return mappedFile.getFileFromOffset();
} else {
return this.rollNextFile(mappedFile.getFileFromOffset());
}
}
return -1;
}
文件不可用
public long rollNextFile(final long offset) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMappedFileSizeCommitLog();
return offset + mappedFileSize - offset % mappedFileSize;
}
根据该offset返回下一个文件的起始偏移量。首先获取一个文件的大小,减去(offset% mappedFileSize)其目的是回到下一文件的起始偏移量。
Step 2:根据偏移量与消息长度查找消息。
首先根据偏移找到所在的物理偏移量,然后用 offset 与文件长度取余得到在文件内的偏移量,从该偏移量读取size长度的内容返回即可。 如果只根据消息偏移查找消息, 则首先找到文件内的偏移量,然后尝试读取4个字节获取消息 的实际长度,最后读取指定字节即可。
public SelectMappedBufferResult getMessage(final long offset, final int size) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMappedFileSizeCommitLog();
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset, offset == 0);
if (mappedFile != null) {
int pos = (int) (offset % mappedFileSize);
return mappedFile.selectMappedBuffer(pos, size);
}
return null;
}
4.5.2 ConsumeQueue 文件
RocketMQ基于主题订阅模式实现消息消费,消费者关心的是一个主题下的所有消息,但由于同一主题的消息不连续地存储在commitlog文件中。设计了消息消费队列文件( Consumequeue),该文件可以看成是 Commitlog关于消息消费的“索引”文件,consumequeue的第一级目录为消息主题,第二级目录为主题的消息队列。
每一个consumequeue条目不会存储全量消息,目的是为了快速检索。
单个ConsumeQueue文件中默认包含30万个条目,单个文件的长度为 30w×20 字节,单个ConsumeQueue文件可以看出是一个ConsumeQueue条目的数组,其下标为ConsumeQueue的逻辑偏移量,消息消费进度存储的偏移量即逻辑偏移量。ConsumeQueue 即为 Commitlog文件的索引文件,其构建机制是当消息到达Commitlog文件后,由专门的线程产生消息转发任务,从而构建消息消费队列文件与下文提到的索引文件。
4.5.3 Index 索引文件
消息消费队列是 RocketMQ专门为消息订阅构建的索引文件,提高根据主题与消息队列检索消息的速度,另外RocketMQ引入了Hash索引机制为消息建立索引。
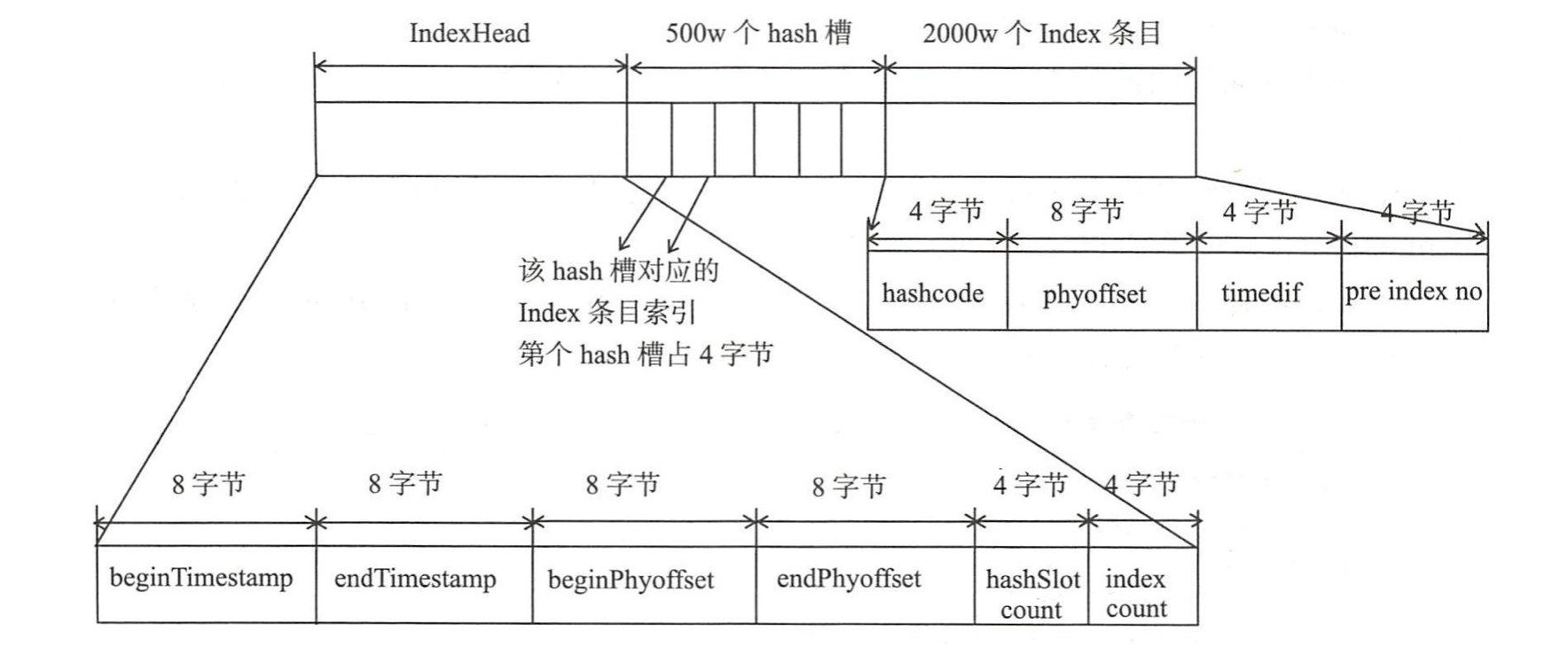
lndexFile总共包含 lndexHeader、Hash槽 、Hash 条目(数据)。
1 ) IndexHeader头部,包含40个字节,记录该IndexFile 的统计信息
beginTimestamp: 该索引文件中包含消息的最小存储时间
endTimestamp: 该索引文件中包含消息的最大存储时间
beginPhyoffset: 该索引文件中包含消息的最小物理偏移量(commitlog文件偏移量)
endPhyoffset:该索引文件中包含消息的最大物理偏移量( commitlog文件偏移量)
hashslotCount: hashslot个数,并不是hash槽使用的个数,在这里意义不大
indexCount: Index条目列表当前已使用的个数,Index条目在Index条目列表中按顺序存储。
2) Hash槽,一个IndexFile默认包含500万个Hash槽,每个Hash槽存储的是落在该Hash槽的hashcode最新的Index的索引
3 )Index条目列表,默认一个索引文件包含 2000万个条目
hashcode: key的hashcode。
phyoffset: 消息对应的物理偏移量
timedif:该消息存储时间与第一条消息的时间戳的差值,小于0该消息无效
prelndexNo:该条目的前一条记录的Index索引,当出现hash冲突时,构建的链表结构
4.5.4 checkpoint文件
checkpoint的作用是记录 Comitlog、ConsumeQueue、Index文件的刷盘时间点,文件
固定长度为4k,其中只用该文件的前面24个字节。

physicMsgTimestamp: commitlog文件刷盘时间点
logicsMsgTimestamp: 消息消费队列文件刷盘时间点
indexMsgTimestamp: 索引文件刷盘时间点
4.6 实时更新消息消费队列与索引文件
当消息生产者提交的消息存储在Commitlog文件中,ConsumeQueue、IndexFile需要及时更新,否则消 息无法及时被消费,根据消息属性查找消息也会出现较大延迟。RocketMQ通过开启一个线程 ReputMessageServcie来准实时转发CommitLog文件更新事件,相应的任务处理器根据转发的消息及时更新 ConsumeQueue、IndexFile文件。
Broker服务器在启动时会启动 ReputMessageService线程,并初始化一个非常关键的参数 reputFfomOffset,该参数的含义是 ReputMessageService从哪个物理偏移量开始转发消息给 ConsumeQueue和IndexFile。如果允许重复转发,reputFromOffset设置为CommitLog的提交指针;如果不允许重复转发,reputFromOffset设置为Commitlog的内存中最大偏移量。
DefaultMessageStore#start
if (this.getMessageStoreConfig().isDuplicationEnable()) {
this.reputMessageService.setReputFromOffset(this.commitLog.getConfirmOffset());
} else {
// It is [recover]'s responsibility to fully dispatch the commit log data before the max offset of commit log.
this.reputMessageService.setReputFromOffset(this.commitLog.getMaxOffset());
}
this.reputMessageService.start();
ReputMessageService线程每执行一次任务推送休息1毫秒就继续尝试推送消息到消息消费队列和索引文件,消息消费转发的核心实现在doReput方法中实现。
DefaultMessageStore#run
@Override
public void run() {
DefaultMessageStore.LOGGER.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
Thread.sleep(1);
this.doReput();
} catch (Exception e) {
DefaultMessageStore.LOGGER.warn(this.getServiceName() + " service has exception. ", e);
}
}
DefaultMessageStore.LOGGER.info(this.getServiceName() + " service end");
}
Step 1 :返回reputFromOffset偏移量开始的全部有效数据(commitlog文件)。然后循环读取每一条消息
//返回reputFromOffset偏移量开始的全部有效数据(commitlog文件)。然后循环读取每一条消息 。
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
Step 2:从result返回的ByteBuffer中循环读取消息,一次读取一条
//从result返回的ByteBuffer中循环读取消息,一次读取一条
DispatchRequest dispatchRequest =
DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false, false);
int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();
Step 3
if (dispatchRequest.isSuccess()) {
//如果消息长度大于0,则调用doDispatch方法
//最终将分别调用CommitLogDispatcherBuildConsumeQueue (构建消息消费队列)、 CommitLogDispatcherBuildIndex(构建索引文件)。
if (size > 0) {
DefaultMessageStore.this.doDispatch(dispatchRequest);
//.....
}
}
其中重点DispatchRequest的核心属性为:
DispatchRequest
public class DispatchRequest {
//消息主题名称
private final String topic;
//消息队列ID
private final int queueId;
//消息物理偏移量
private final long commitLogOffset;
//消息长度
private int msgSize;
//消息过滤 tag hashcode
private final long tagsCode;
//消息存储时间戳
private final long storeTimestamp;
//消息队列偏移量
private final long consumeQueueOffset;
//消息索引key。多个索引key用空格隔开
private final String keys;
//是否成功解析到完整的消息
private final boolean success;
//消息唯一键
private final String uniqKey;
//消息系统标记
private final int sysFlag;
//消息预处理事务偏移量
private final long preparedTransactionOffset;
//消息属性
private final Map<String, String> propertiesMap;
//位图
private byte[] bitMap;
private int bufferSize = -1;//the buffer size maybe larger than the msg size if the message is wrapped by something
// for batch consume queue
private long msgBaseOffset = -1;
private short batchSize = 1;
private long nextReputFromOffset = -1;
}
4.6.1 根据消息更新 ConumeQueue
消息消费队列转发任务实现类为 : CommitLogDispatcherBuildConsumeQueue,内部最
终将调用 putMessagePositioninfo方法。
Step 1:根据消息主题与队列ID,先获取活创建对应的ConumeQueue文件
putMessagePositionInfoWrapper
public void putMessagePositionInfoWrapper(DispatchRequest dispatchRequest) {
ConsumeQueueInterface cq = this.findOrCreateConsumeQueue(dispatchRequest.getTopic(), dispatchRequest.getQueueId());
this.putMessagePositionInfoWrapper(cq, dispatchRequest);
}
*每一个消息主题对应一个消息消费队列目录然后主题下每一个消息队列对应一个文件夹,然后取出该文件夹最后的ConsumeQueue文件即可 *
Step 2:
putMessagePositionInfo
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
if (offset + size <= this.maxPhysicOffset) {
log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);
return true;
}
//依次将消息偏移量、消息长度、tag hashcode写入到ByteBuffer中
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
final long expectLogicOffset = cqOffset * CQ_STORE_UNIT_SIZE;
//consumeQueueOffset计算ConsumeQueue中的物理地址,将内容追加到ConsumeQueue的内
//存映射文件中(本操作只追击并不刷盘),ConsumeQueue的刷盘方式固定为异步刷盘模式
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(expectLogicOffset);
if (mappedFile != null) {
//......
this.maxPhysicOffset = offset + size;
return mappedFile.appendMessage(this.byteBufferIndex.array());
}
return false;
}
4.6.2 根据消息更新 Index索引文件
Hash索引文件转发任务实现类 : CommitLogDispatcherBuildlndex
CommitLogDispatcherBuildIndex
class CommitLogDispatcherBuildIndex implements CommitLogDispatcher {
@Override
//如果messsagelndexEnable设置为true,则调用IndexService#buildlndex构建Hash索引,否则忽略本次转发任务 。
public void dispatch(DispatchRequest request) {
if (DefaultMessageStore.this.messageStoreConfig.isMessageIndexEnable()) {
DefaultMessageStore.this.indexService.buildIndex(request);
}
}
}
Step1:获取或创建IndexFile文件并获取文件最大物理偏移量。如果该消息的物理偏移量小于索引文件中的物理偏移,则说明是重复数据,忽略本次索引构建。
Step2 :如果消息的唯一键不为空,则添加到 Hash索引中,以便加速根据唯一键检索消息。
Step3:构建索引键,RocketMQ 支持为同一个消息建立多个索引,多个索引键空格分开
buildIndex
public void buildIndex(DispatchRequest req) {
//获取或创建IndexFile文件并获取文件最大物理偏移量
IndexFile indexFile = retryGetAndCreateIndexFile();
if (indexFile != null) {
long endPhyOffset = indexFile.getEndPhyOffset();
DispatchRequest msg = req;
String topic = msg.getTopic();
String keys = msg.getKeys();
//如果该消息的物理偏移量小于索引文件中的物理偏移,则说明是重复数据,忽略本次索引构建。
if (msg.getCommitLogOffset() < endPhyOffset) {
return;
}
final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
switch (tranType) {
case MessageSysFlag.TRANSACTION_NOT_TYPE:
case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
break;
case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
return;
}
//如果消息的唯一键不为空,则添加到 Hash索引中,以便加速根据唯一键检索消息
if (req.getUniqKey() != null) {
indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()));
if (indexFile == null) {
LOGGER.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
return;
}
}
//Step3:构建索引键,RocketMQ 支持为同一个消息建立多个索引,多个索引键空格分开
if (keys != null && keys.length() > 0) {
String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
for (int i = 0; i < keyset.length; i++) {
String key = keyset[i];
if (key.length() > 0) {
indexFile = putKey(indexFile, msg, buildKey(topic, key));
if (indexFile == null) {
LOGGER.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
return;
}
}
}
}
} else {
LOGGER.error("build index error, stop building index");
}
}
4.7 消息队列与索引文件恢复
RocketMQ存储首先将消息全量存储在Commitlog文件中,然后异步生成转发任务更新ConsumeQueue、Index文件。 如果消息成功存储到 Commitlog 文件中,转发任务未成功执行,此时消息服务器Broker由于某个原因宕机,导致Commitlog、ConsumeQueue、IndexFile文件数据不一致。如果不加以人工修复的话,会有一部分消息即便在Commitlog文件中存在,但由于并没有转发到 Consumequeue,这部分消息将永远不会被消费者消费 。 那RocketMQ 是如何使Commitlog、消息消费队列(ConsumeQueue)达到最终一致性的呢?
Step1:判断上一次退出是否正常。
其实现机制是Broker在启动时创建${ROC口T_ HOME}/store/abort文件,在退出时通过注册JVM钩子函数删除abort文件。如果下一次启动时存在abort文件。说明Broker是异常退出的 Commitlog与Consumequeue 数据有可能不一致,需要进行修复。
isTempFileExist
private boolean isTempFileExist() {
String fileName = StorePathConfigHelper.getAbortFile(this.messageStoreConfig.getStorePathRootDir());
File file = new File(fileName);
return file.exists();
}
Step2:加载延迟队列
Step3 :加载Commitlog文件
MappedFileQueue#doLoad
public boolean doLoad(List<File> files) {
// ascending order
files.sort(Comparator.comparing(File::getName));
for (File file : files) {
//如果文件大小与配置文件的单个文件大小不一致,将忽略该目录下所有文件,
if (file.length() != this.mappedFileSize) {
log.warn(file + "\t" + file.length()
+ " length not matched message store config value, please check it manually");
return false;
}
try {
MappedFile mappedFile = new DefaultMappedFile(file.getPath(), mappedFileSize);
//指针都设置为文件大小
mappedFile.setWrotePosition(this.mappedFileSize);
mappedFile.setFlushedPosition(this.mappedFileSize);
mappedFile.setCommittedPosition(this.mappedFileSize);
this.mappedFiles.add(mappedFile);
log.info("load " + file.getPath() + " OK");
} catch (IOException e) {
log.error("load file " + file + " error", e);
return false;
}
}
return true;
}
Step4 :加载消息消费队列
Steps :加载存储检测点,检测点主要记录commitlog文件、Consumequeue文件、Index索引文件的刷盘点,将在下文的文件刷盘机制中再次提交。
加载存储检测点
this.storeCheckpoint =
new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));
this.masterFlushedOffset = this.storeCheckpoint.getMasterFlushedOffset();
this.indexService.load(lastExitOK);
Step6 :加载索引文件,如果上次异常退出,而且索引文件上次刷盘时间小于该索引文件最大的消息时间戳该文件将立即销毁。
this.indexService.load(lastExitOK);
public boolean load(final boolean lastExitOK) {
File dir = new File(this.storePath);
File[] files = dir.listFiles();
if (files != null) {
// ascending order
Arrays.sort(files);
for (File file : files) {
try {
IndexFile f = new IndexFile(file.getPath(), this.hashSlotNum, this.indexNum, 0, 0);
f.load();
if (!lastExitOK) {
if (f.getEndTimestamp() > this.defaultMessageStore.getStoreCheckpoint()
.getIndexMsgTimestamp()) {
f.destroy(0);
continue;
}
}
this.indexFileList.add(f);
} catch (IOException e) {
return false;
} catch (NumberFormatException e) {
}
}
}
return true;
}
Step7 :根据Broker是否是正常停止执行不同的恢复策略
恢复策略
private void recover(final boolean lastExitOK) {
long recoverCqStart = System.currentTimeMillis();
long maxPhyOffsetOfConsumeQueue = this.recoverConsumeQueue();
long recoverCqEnd = System.currentTimeMillis();
if (lastExitOK) {
this.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue);
} else {
this.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue);
}
long recoverClogEnd = System.currentTimeMillis();
this.recoverTopicQueueTable();
long recoverOffsetEnd = System.currentTimeMillis();
}
Step8:恢复 ConsumeQueue 文件后,将在CommitLog实例中保存每个消息消费队列当前的存储逻辑偏移量
4.7.1 Broker 正常停止文件恢复
Step1 : Broker正常停止再重启时,从倒数第三个文件开始进行恢复,如果不足3个文件,则从第一个文件开始恢复。checkCRCOnRecover参数设置在进行文件恢复时查找消息时是否验证CRC。
Step2:遍历Commitlog文件,每次取出一条消息, 如果查找结果为true并且消息的长度大于0表示消 息正确,mappedFileOffset 指针向前移动本条消 息的长 度; 如果查找结果为true并且消息的长度等于0,表示已到该文件的末尾,如果还有下一个文件,则重置processOffset、mappedFileOffset重复步骤3,否则跳出循环; 如果查找结构为false,表明该文件未填满所有消息,跳出循环,结束遍历文件。
Step3: 更新MappedFileQueue的flushedWhere与commiteedWhere指针
Step4:删除offset之后的所有文件
4.7.2 Broker 异常停止文件恢复
异常文件恢复的 步骤与正常停止文件恢复的流程基本相同,其主要差别有两个。首先正常停止默认从倒数第三个文件开始进行恢复,而异常停止则需要从最后一个文件往前走,找到第一个消息存储正常的文件 。 其次,如果commitlog目录没有消息文件,如果在消息消费队列目录下存在文件,则需要销毁。
如何判断一个消息文件是一个正确的文件呢?
Step1 :首先判断文件的魔数,如果不是MESSAGE MAGIC_CODE,返回false,表示该文件不符合commitlog消息文件的存储格式。
isMappedFileMatchedRecover
int magicCode = byteBuffer.getInt(MessageDecoder.MESSAGE_MAGIC_CODE_POSITION);
if (magicCode != MESSAGE_MAGIC_CODE) {
return false;
}
Step2 :如果文件中第一条消息的存储时间等于0,返回false,说明该消息存储文件中未存储任何消息。
Step3 :对比文件第一条消息的时间戳与检测点,文件第一条消息的时间戳小于文件检测点说明该文件部分消息是可靠的,则从该文件开始恢复。
Step4 :如果根据前3步算法找 到 MappedFile,则遍历MappedFile中的消息,验证消息的合法性,并将消息重新转发到消息消费队列与索引文件
Step5 :如果未找到有效 MappedFile,则设置commitlog目录的flushedWhere、committedWhere指针都为0,并销毁消息消费队列文件。
4.8 文件刷盘机制
RocketMQ 的存储与读写是基于 JDK NIO 的内存映射机制,消息存储时首先将消息追加到内存,再根据配置的刷盘策略在不同时间进行刷写磁盘。如果是同步刷盘,消息追加到内存后,将同步调用MappedByteBuffer的force()方法;如果是异步刷盘,在消息追加到内存后立刻返回给消息发送端。RocketMQ使用一个单独的线程按照某一个设定的频率执行刷盘操作。
索引文件的刷盘并不是采取定时刷盘机制,而是每更新一次索引文件就会将上一次的改动刷写到磁盘
4.8.1 Broker 同步刷盘
同步刷盘,指的是在消息追加到内存映射文件的内存中后,立即将数据从内存刷写到磁盘文件,由 CommitLog的handleDiskFlush方法实现。
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(), CommitLog.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
service.putRequest(request);
CompletableFuture<PutMessageStatus> flushOkFuture = request.future();
PutMessageStatus flushStatus = null;
try {
flushStatus = flushOkFuture.get(CommitLog.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout(),
TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
//flushOK=false;
}
if (flushStatus != PutMessageStatus.PUT_OK) {
putMessageResult.setPutMessageStatus(PutMessageStatus.FLUSH_DISK_TIMEOUT);
}
}
同步刷盘实现流程如下:
- 构建 GroupCommitRequest 同步任务并提交到 GroupCommitRequest。
- 等待同步刷盘任务完成,如果超时则返回刷盘错误, 刷盘成功后正常返回给调用方。
其中GroupCommitRequest的核心属性有:
//刷盘点偏移量
private final long nextOffset;
//刷盘结果 true or false
private final CompletableFuture<PutMessageStatus> flushOKFuture = new CompletableFuture<>();
private volatile int ackNums = 1;
private final long deadLine;
消费发送线程将消息追加到内存映射文件后,将同步任务 GroupCommitRequest 提交到 GroupCommitService线程,然后调用阻塞等待刷盘结果,超时时间默认为 5s。消费发送线程将消息追加到内存映射文件后,将同步任务 GroupCommitRequest 提交到 GroupCommitService线程,然后调用阻塞等待刷盘结果,超时时间默认为 5s。
GroupCommitService线程处理 GroupCommitRequest对象后将调用 wakeupCustomer方
法将消费发送线程唤醒,并将刷盘告知 GroupCommitRequest。
GroupCommitService
//同步刷盘任务暂存容器
private volatile LinkedList<GroupCommitRequest> requestsWrite = new LinkedList<GroupCommitRequest>();
//GroupCommitService 线 程每次处理的 request容器,避免了任务提交与任务执行的锁冲突。
private volatile LinkedList<GroupCommitRequest> requestsRead = new LinkedList<GroupCommitRequest>();
private final PutMessageSpinLock lock = new PutMessageSpinLock();
GroupCommitService#putRequest
public synchronized void putRequest(final GroupCommitRequest request) {
lock.lock();
try {
this.requestsWrite.add(request);
} finally {
lock.unlock();
}
this.wakeup();
}
public void wakeup() {
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
}
客户端提交同步刷盘任务到 GroupCommitService线程,如果废线程处于等待状态则将其唤醒。
GroupCommitService#swapRequests
private void swapRequests() {
lock.lock();
try {
LinkedList<GroupCommitRequest> tmp = this.requestsWrite;
this.requestsWrite = this.requestsRead;
this.requestsRead = tmp;
} finally {
lock.unlock();
}
}
由于避免同步刷盘消费任务与其他消息生产者提交任务直接的锁竞争, GroupCommitService 提供读容器与写容器,这两个容器每执行完一次任务后,交互,继续消费任务。
GroupCommitService#run
public void run() {
CommitLog.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
this.waitForRunning(10);
this.doCommit();
} catch (Exception e) {
CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);
}
}
// Under normal circumstances shutdown, wait for the arrival of the
// request, and then flush
try {
Thread.sleep(10);
} catch (InterruptedException e) {
CommitLog.log.warn("GroupCommitService Exception, ", e);
}
synchronized (this) {
this.swapRequests();
}
this.doCommit();
CommitLog.log.info(this.getServiceName() + " service end");
}
GroupCommitService每处理一批同步刷盘请求( requestsRead容器中请求)后休息10ms, 然后继续处理下一批,其任务的核心实现为doCommit 方法 。
GroupCommitService#doCommit
private void doCommit() {
if (!this.requestsRead.isEmpty()) {
for (GroupCommitRequest req : this.requestsRead) {
// There may be a message in the next file, so a maximum of
// two times the flush
boolean flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();
for (int i = 0; i < 2 && !flushOK; i++) {
CommitLog.this.mappedFileQueue.flush(0);
flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();
}
req.wakeupCustomer(flushOK ? PutMessageStatus.PUT_OK : PutMessageStatus.FLUSH_DISK_TIMEOUT);
}
long storeTimestamp = CommitLog.this.mappedFileQueue.getStoreTimestamp();
if (storeTimestamp > 0) {
CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(storeTimestamp);
}
this.requestsRead = new LinkedList<>();
} else {
// Because of individual messages is set to not sync flush, it
// will come to this process
CommitLog.this.mappedFileQueue.flush(0);
}
}
执行刷盘操作,即调用 MappedByteBuffer#force方法。
同步刷盘的简单描述就是,消息 生产者在消息服务端 将消息内容追加到内存映射 文件中(内存)后,需 要 同步将内存的内容立刻刷写到磁盘 。 通过调用内存映射文件 (MappedByteBuffer的 force方法)可将内存中的数据写入磁盘。
4.8.2 Broker异步刷盘
异步刷盘根据是否开启== transientStorePoolEnable ==机制,如果 transientStorePoolEnable 为 true, RocketMQ 会单独申请一个与目标物理文 件 ( commitlog) 同样大小的堆外内存, 该堆外内存将使用 内存锁定,确保不会被 置换到虚 拟内存中 去,消 息首先追加到堆外内存,然后提交到与物理文件的内存映射内存中,再 flush 到磁盘。如果 transientStorePoolEnable 为 flalse,消息直接追加到与物理文件直接映射的内存中,然后刷写到磁盘中。
Commitlog#handleDiskFlush
// 异步刷盘
else {
if (!CommitLog.this.defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
flushCommitLogService.wakeup();
} else {
commitLogService.wakeup();
}
}
transientStorePoolEnable为 true 的磁盘刷写流程如图如下:
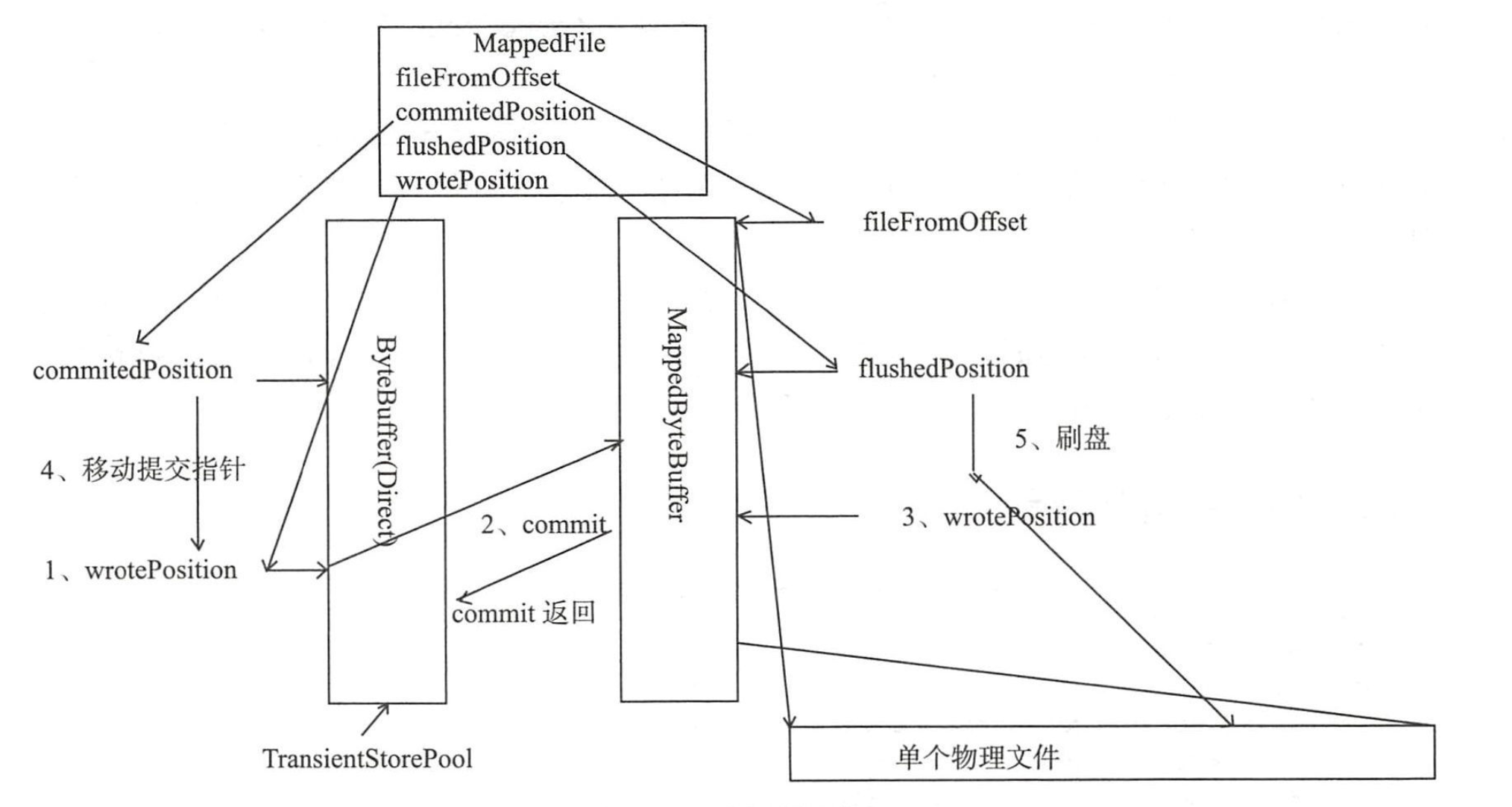
- 首先将消息直接追加到 ByteBuffer (堆外内存 DirectByteBuffer), wrotePosition 随着消息的不断追加向后移动。
- CommitRealTimeService 线程默认每 200ms 将 ByteBuffer新追加的内容( wrotePosihon 减去 commitedPosition)的数据提交到 MappedByteBuffer中。
- MappedByteBuffer 在内存中追加提交的内容, wrotePosition 指针向前后移动, 然后 返回 。
- commit 操作成功返回,将 commitedPosition 向前后移动本次提交的内容长度,此时 wrotePosition 指针依然可以向前推进 。
- FlushRealTimeService线程默认每500ms将MappedByteBuffer中新追加的内存( wrotePosition减去上一次刷写位置 flushedPositiont)通过调用 MappedByteBuffer#force()方法将数据刷写到磁盘 。
CommitRealTimeService 提交钱程工作机制
Commitlog$CommitRealTimeService#run
//CommitRealTimeService 线程间隔时间,默认 200ms
int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitIntervalCommitLog();
//一次提交任务至少包含页数,如果待提交数据不足,小于该参数配置的值,将忽略本次提交任务,默认4 页。
int commitDataLeastPages = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitCommitLogLeastPages();
//两次真实提交最大间隔,默认 200ms。
int commitDataThoroughInterval =
CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitCommitLogThoroughInterval();
如果距上次提交间隔超过 commitDataThoroughlnterval, 则本次提交忽略commit
CommitLogLeastPages参数, 也就是如果待提交数据小于指定页数, 也执行提交操作 。
boolean result = CommitLog.this.mappedFileQueue.commit(commitDataLeastPages);
long end = System.currentTimeMillis();
if (!result) {
this.lastCommitTimestamp = end; // result = false means some data committed.
CommitLog.this.flushManager.wakeUpFlush();
}
CommitLog.this.getMessageStore().getPerfCounter().flowOnce("COMMIT_DATA_TIME_MS", (int) (end - begin));
if (end - begin > 500) {
log.info("Commit data to file costs {} ms", end - begin);
}
this.waitForRunning(interval);
执行提交操作,将待提交数据提交到物理文件的内存映射内存区,如果返回 false,并不是代表提交失败,而是只提交了一部分数据,唤醒刷盘线程执行刷盘操作。 该线程每完成一次提交动作,将等待 200ms 再继续执行下一次提交任务 。
FlushRealTimeService 刷盘线程工作机制
Commitlog$FlushRealTimeService#run
//默认为 false, 表示 await方法等待;如果为 true,表示使 用 Thread.sleep 方法等待 。
boolean flushCommitLogTimed = CommitLog.this.defaultMessageStore.getMessageStoreConfig().isFlushCommitLogTimed();
//FlushRealTimeService 线程任务运行间隔 。
int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushIntervalCommitLog();
//一次刷写任务至少包含页数, 如 果待 刷 写数据不足, 小于该参数配置的值,将忽略本次刷写任务,默认 4页。
int flushPhysicQueueLeastPages = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogLeastPages();
//两次真实刷写任务最大间隔, 默认 10s。
int flushPhysicQueueThoroughInterval =
CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogThoroughInterval();
Commitlog$FlushRealTimeService#run
long currentTimeMillis = System.currentTimeMillis();
if (currentTimeMillis >= (this.lastFlushTimestamp + flushPhysicQueueThoroughInterval)) {
this.lastFlushTimestamp = currentTimeMillis;
flushPhysicQueueLeastPages = 0;
printFlushProgress = (printTimes++ % 10) == 0;
}
如果距上次提交间隔超过 flushPhysicQueueThoroughinterval,则本次刷盘任务 将忽略flushPhysicQueueLeastPages, 也就是如果待刷写数据小于指定页数也执行刷写磁盘 操作。
Commitlog$FlushRealTimeService#run
if (flushCommitLogTimed) {
Thread.sleep(interval);
} else {
this.waitForRunning(interval);
}
执行一次刷盘任务前先等待指定时间间隔, 然后再执行刷盘任务。
Commitlog$FlushRealTimeService#run
long begin = System.currentTimeMillis();
CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages);
long storeTimestamp = CommitLog.this.mappedFileQueue.getStoreTimestamp();
if (storeTimestamp > 0) {
CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(storeTimestamp);
}
调用flush方法将内存中数据刷写到磁盘,并且更新存储检测点文件的commitlog文件的更新时间戳,文件检测点文件( checkpoint 文件)的刷盘动作在刷盘消息消费队列线程中执行, 其入口为 DefaultMessageStore#FlushConsumeQueueService。
4.9 过期文件删除机制
由于 RocketMQ 操作 CommitLog、 ConsumeQueu巳文件是基于内存映射机制并在启动 的时候会 加载 commitlog、 ConsumeQueue 目录下的所有文件,为了避免内存与磁盘的浪 费,不可能将消息永久存储在消息服务器上,所以需要引人一种机制来删除己过期的文件 。
RocketMQ 顺序写 Commitlog文件、 ConsumeQueue文件,所有写操作全部落在最后一个 CommitLog 或 ConsumeQueue 文件上,之前的文件在下一个文件创建后将不会再被更新。RocketMQ清除过期文件的方法是 :如果非当前写文件在一定时间间隔内没有再次被更新, 则认为是过期文件,可以被删除,RocketMQ 不会关注这个文件上的消息是否全部被消费。默认每个文件的过期时间为72小时,通过在Broker配置文件中设fileReservedTime来改变过期时间,单位为小时。
DefaultMessageStore#addScheduleTask
this.scheduledExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.getBrokerIdentity()) {
@Override
public void run2() {
DefaultMessageStore.this.cleanFilesPeriodically();
}
}, 1000 * 60, this.messageStoreConfig.getCleanResourceInterval(), TimeUnit.MILLISECONDS);
RocketMQ会每隔 10s调度一次 cleanFilesPeriodically, 检测是否需要清除过期文件。 执行频率可以通过设置 cleanResourcelnterval,默认为10s。
private void cleanFilesPeriodically() {
this.cleanCommitLogService.run();
this.cleanConsumeQueueService.run();
this.correctLogicOffsetService.run();
}
分别执行清除消息存储文件( Commitlog文件)与消息消费队列文件 (ConsumeQueue 文件)。
DefaultMessageStore$CleanCommitLog Service#deleteExpiredFiles。
//文件保留时间,也就是从最后一次更新时间到现在,如果超过了该时间, 则认为是过期文件,可以被删除。
long fileReservedTime = DefaultMessageStore.this.getMessageStoreConfig().getFileReservedTime();
//删除物理文件的间隔,因为在一次清除过程中, 可能需要被删除的文件不止一个,该值指定两次删除文件的问隔时间。
int deletePhysicFilesInterval = DefaultMessageStore.this.getMessageStoreConfig().getDeleteCommitLogFilesInterval();
//在清除过期文件时,如果该文件被其他线程所占用(引用次数大于0,比如读取消息),此时会阻止此次删除任务,同时在第一次试图删除该文件时记录当前时间戳,destroyMapedFilelntervalForcibly表示第一次拒绝删除之后能保留的最大时间,在此时间内,同样可以被拒绝删除, 同时会将引用减少1000个,超过该时间间隔后,文件将被强制删除 。
int destroyMappedFileIntervalForcibly = DefaultMessageStore.this.getMessageStoreConfig().getDestroyMapedFileIntervalForcibly();
int deleteFileBatchMax = DefaultMessageStore.this.getMessageStoreConfig().getDeleteFileBatchMax();
boolean isTimeUp = this.isTimeToDelete();
boolean isUsageExceedsThreshold = this.isSpaceToDelete();
boolean isManualDelete = this.manualDeleteFileSeveralTimes > 0;
if (isTimeUp || isUsageExceedsThreshold || isManualDelete) {
// 继续执行删除逻辑
}else{
// 本次删除任务无作为 。
}
RocketMQ在如下三种情况任意之一满足的情况下将继续执行删除文件操作:
- 指定删除文件的时间点, RocketMQ通过deleteWhen设置一天的固定时间执行一次删除过期文件操作, 默认为凌晨4点。
- 磁盘空间是否充足,如果磁盘空间不充足,则返回true,表示应该触发过期文件删除操作。
- 预留,手工触发,可以通过调用 excuteDeleteFilesManualy方法手工触发过期文件删除。