ThreadLocal简介
一、ThreadLocal简介
ThreadLocal顾名思义可以根据字面意思理解成线程本地变量。也就是说如果定义了一个ThreadLocal,每个线程都可以在这个ThreadLocal中读写,这个读写是线程隔离的,线程之前不会有影响。
每个Thread都维护自己的一个ThreadLocalMap ,所以是线程隔离的。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
通过这个ThreadLocalMap实现数据的读写,既然是Map肯定有key和value,但是这个ThreadLocalMap的key可以简单的看成是ThreadLocal,实际是并不是ThreadLocal的本身,而是它的一个弱引用。
二、ThreadLocal方法和成员变量
API
ThreadLocal的API很少就包含了4个,分别是get()、set()、remove()、withInitial(),源码如下:
public T get() {}
public void set(T value){}
public void remove(){}
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
}
- get():获取当前线程对应的ThreadLocalMap存储的值,key为当前TheadLocal(实际为TheadLocal的弱引用),也就是获取当前线程本地变量的值。
- set(T value):给当前线程对应的ThreadLocalMap的设置值,也就是给当前线程本地变量设置值。
- remove():清除前线程对应的ThreadLocalMap存储的TheadLocal,也就是清除当前线程本地变量的值。
- withInitial():用于创建一个线程局部变量,变量的初始化值通过调用Supplier的get方法来确定
成员变量
// 调用nextHashCode()方法获取下一个hashCode值,用于计算ThreadLocalMap.tables数组下标
// key.threadLocalHashCode & (len - 1)
private final int threadLocalHashCode = nextHashCode();
// 原子类,用于计算hashCode值
private staitc AmoicInteger nextHashCode = new AmoicInteger();
// hash增量值,斐波那契数也叫黄金分割数,可以让hash值分布非常均匀
private static final int HASH_INCREMENT = 0x61c88647;
// 获取下一个hashCode值方法,只用原子类操作
private static int nextHashCode () {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
三、ThreadLocalMap
ThreadLocalMap是ThreadLocal类的一个静态内部类,在上面有说到每个线程都维护着一个ThreadLocalMap,这个`ThreadLocalMap 就是用来储存数据的。
ThreadLocalMap内部维护着一个Entry节点,这个节点继承了WeakReference类,泛型为ThreadLocal表示是弱引用,节点内部定义了一个为Object的value,这个value就是我们存放的值,Entry类的构造方法只有一个,传入key和value,这个key就是ThreadLocal,实际为ThreadLocal的弱引用。
static class Entry extends WeakReference<ThreacLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v){
super(k);
value = v;
}
}
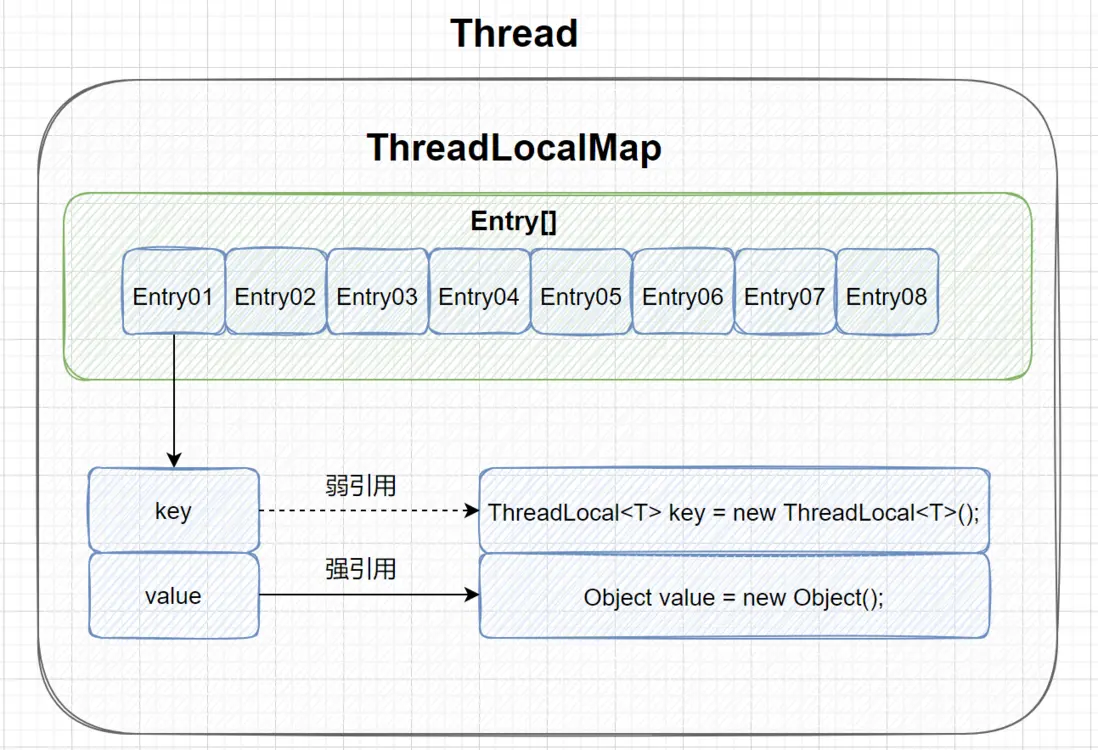
Thread、ThreadLocalMap、ThreadLocal结构关系
每个Thread都有一个ThreadLocalMap变量,ThreadLocalMap内部定义了Entry节点类,这个节点继承了WeakReference类泛型为ThreacLocal类,节点类的构造方法ThreadLocal<?> k, Object v,所以可以得到下面的结构关系图:
GC之后key是否为null?
既然ThreadLocalMap的key是弱引用,GC之后key是否为null?在搞清楚这个问题之前,我们需要先搞清楚Java的四种引用类型:
-
强引用:new出来的对象就是强引用,只要强引用存在,垃圾回收器就永远不会回收被引用的对象,哪怕内存不足的时候。
-
软引用:使用SoftReference修饰的对象被称为软引用,在内存要溢出的时候软引用指向的对象会被回收。
-
弱引用:使用WeakReference修饰的对象被称为弱引用,只要发生垃圾回收,被弱引用指向的对象就会被回收。
-
虚引用:虚引用是最弱的引用,用PhantomReference进行定。唯一的作用就是用来队列接受对象即将死亡的通知。
**这个问题的答案是不为null **,可以看下面的图
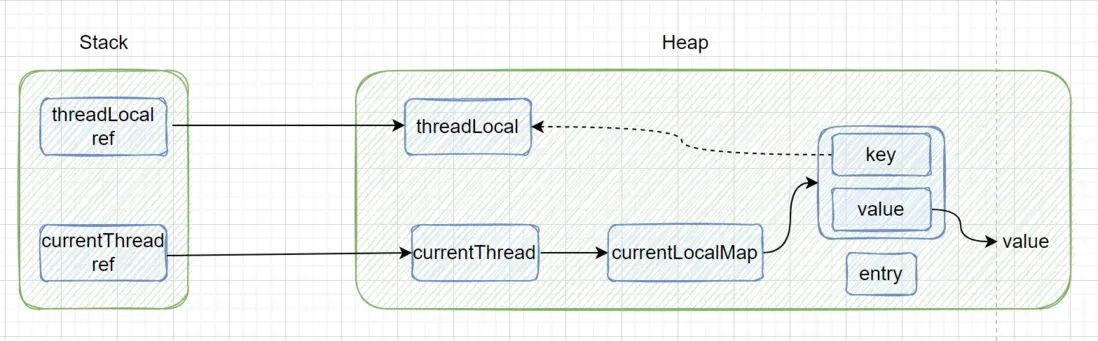
通过上图我们知道ThreadLocal的强引用是仍然存在的,所以不会被回收,不为null
ThreadLocalMap成员变量
// 初始化容量 必须为2的幂,位运算取代模运算提升计算效率,可以试hash值发生碰撞的概率更小,尽可能的使
// 元素在哈希表中均匀的散列
private static final int INITTAL_CAPACIRY = 16;
// Entry表
private Entry[] table;
// Entry表存放的元素数量
private int size = 0;
// 扩容阙值
private int threshold;
四、ThreadLocal.set()方法源码详解
set()方法
pubic void set(T value) {
// 获取当前线程
Thread t = Threac.currentThread();
// 获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
// 如果map不为null, 调用ThreadLocalMap.set()方法设置值
if (map != null)
map.set(this, value);
else
// map为null,调用createMap()方法初始化创建map
createMap(t, value);
}
// 返回线程的ThreadLocalMap.threadLocals
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 调用ThreadLocalMap构造方法创建ThreadLocalMap
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
// ThreadLocalMap构造方法,传入firstKey, firstValue
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化Entry表的容量 = 16
table = new Entry[INITIAL_CAPACITY];
// 获取ThreadLocal的hashCode值与运算得到数组下标
int i = firsetKey.threadLocalHashCode & (INITAL_CAPACITY - 1);
// 通过下标Entry表赋值
table[i] = new Entry(firstKey, firstValue);
// Entry表存储元素数量初始化为1
size = 1;
// 设置Entry表扩容阙值 默认为 len * 2 / 3
setThreshold(INITIAL_CAPACITY);
}
private void setThreshold(int len) {
threshold = len * 2 / 3
}
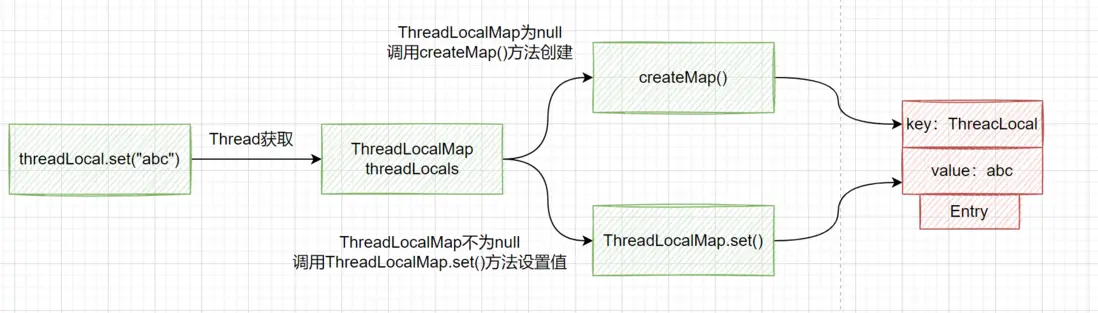
ThreadLocal.set()方法还是很简单的,核心方法在ThreadLocalMap.set()方法,ThreadLocal.set()方法流程如下:
- 获取当前线程的ThreadLocalMap map 。
- 如果map不为null则调用map.set()方法设置值。
- 如果map为null则调用createMap方法创建。
- createMap()方法通过ThreadLocalMap的构造方法创建,构造方法主要做了初始化Entry[] table容量16,通过ThreadLocal的threadLocalHashCode调用nextHashCode()方法获取hashCode值计算出下标,table数组通过下标赋值,初始化存储的元素数量,初始化数组扩容阙值。
ThreadLocalMap在构造方法里处理的时候用到hash算法,源码如下:
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
这里最关键的就是threadLocalHashCode值的计算,ThreadLocal中有一个属性为HASH_INCREMENT = 0x61c88647,每创建一个ThreadLocal就会调用一次nextHashCode()方法,这个HASH_INCREMENT值就会增长0x61c88647,这个值很特殊,是斐波那契数也叫黄金分割数,这个值可以让hash分布非常均匀。
ThreadLocalMap.set()方法分为好几种情况,主要有以下四种情况,针对不同的情况我们通过画图来说明。
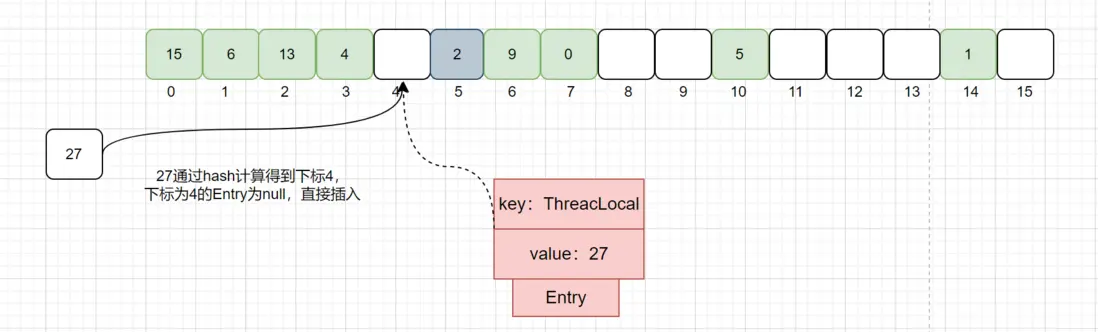
说明: 下面所有图中,绿色块Entry代表正常数据,灰色代表Entry的key值为null,已被GC回收,白色代表Entry为null。
第一种情况:通过hash计算得到的下标,该下标对应的Entry为null,这种情况直接将该数据放入该槽位即可。
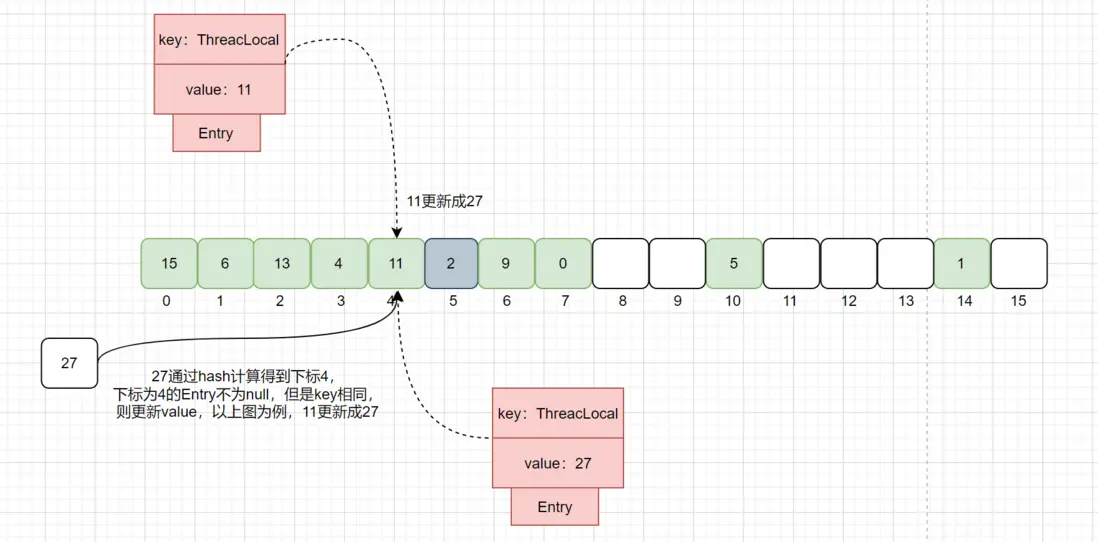
第二种情况:通过hash计算得到的下标,该下标对应的Entry不为null,但是key相同,这种情况直接更新该槽位的value值。
第三种情况:通过hash计算得到的下标,该下标对应的Entry不为null,且key不相同,这种时候会遍历数组,线性往后查找,查找Entry为null的槽位,且在找到Entry为null之前没有遇到key过期的Entry,就该数据放入该槽位中,如果遍历过程中,遇到了key相等的槽位,直接更新value即可:
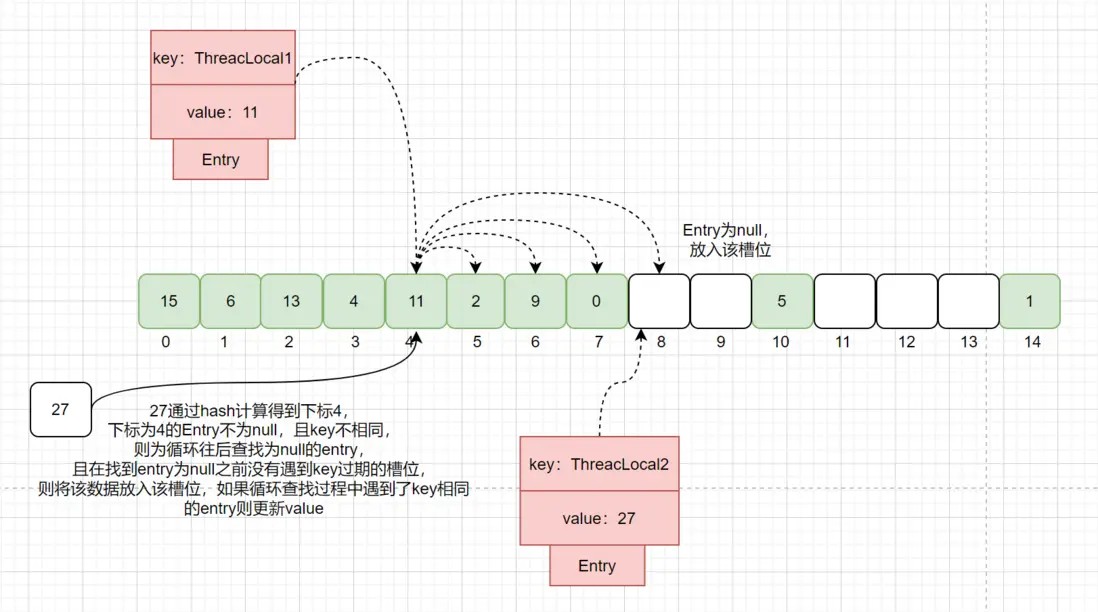
注意:每次循环查找都会判断key是否相等,如果相等则更新value直接返回。
第四种情况:基于第三种情况,如果在找到Entry为null之前遇到了key过期的Entry,如下图:
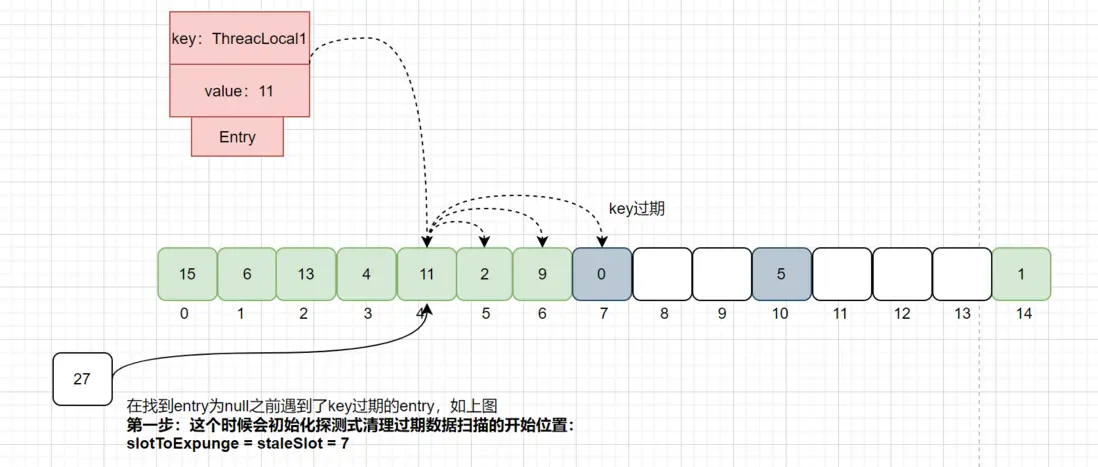
如上图散列数组下标为7位置对应的Entry数据key为null,说明此数据key值已经被垃圾回收掉了,此时会执行replaceStaleEntry()方法,该方法含义是替换过期数据的逻辑,以index=7为起点开始向前遍历,进行探测式数据清理工作。
初始化探测式清理过期数据扫描的开始位置:slotToExpunge = stateSlot = 7。
以当前stateSlot 开始向前迭代找到,找到其他过期的数据,然后更新过期数据起始扫描下标的slotToExpunge ,直到找到了Entry为null的槽位则结束。
如果找到过期数据,继续向前迭代,直到遇到Entry=null的槽位则停止迭代。
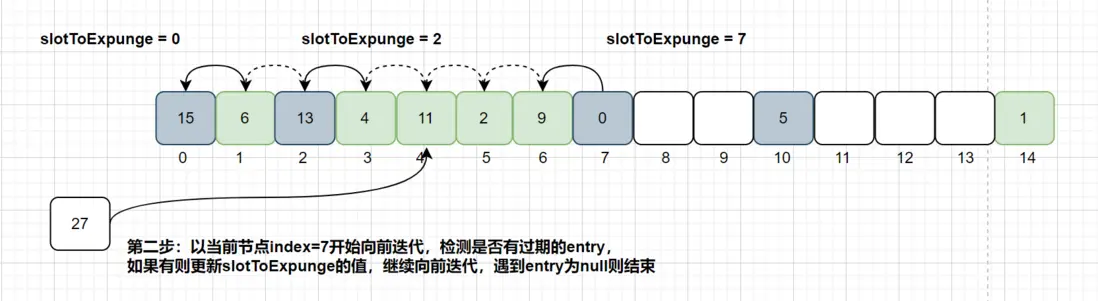
上图以当前节点index = 7向前迭代,检测是否有过期的Entry数据,如果有则更新slotToExpunge的值,遇到Entry为null则结束探测,以上图为例slotToExpunge被更新为0。
上面向前迭代的操作是为了更新探测清理过期数据的起始位置soltToExpunge的值,这个值是用来判断当前过期槽位staleSlot之前是否还有过期元素。
接着开始staleSolt位置index = 7向后迭代,如果找到了相等key的Entry的数据则更新value值,如下图:
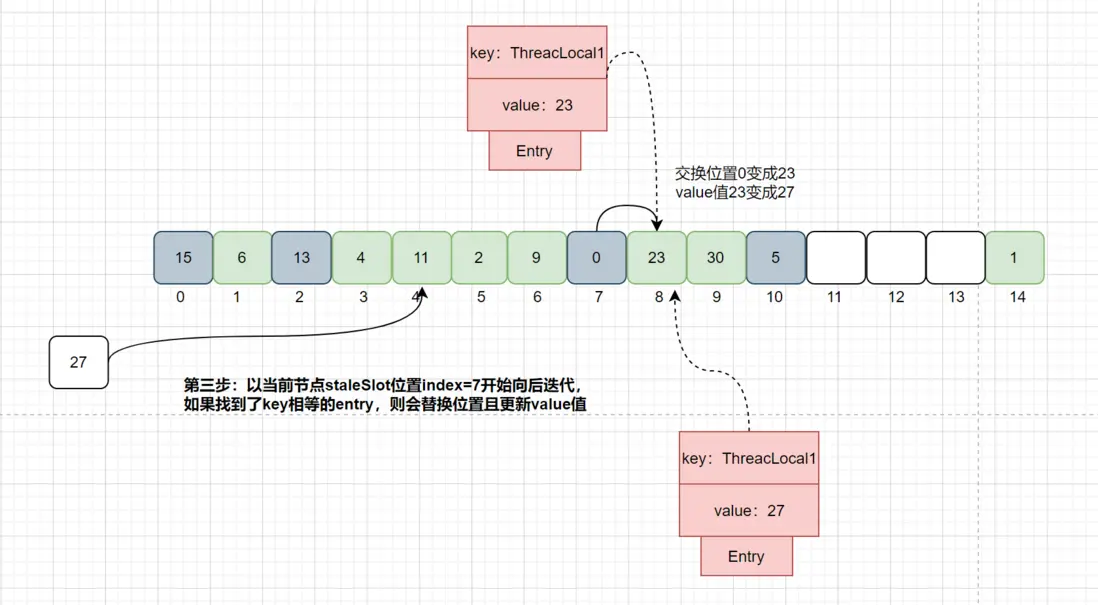
从当前节点staleSolt位置开始向后寻找key相等的Entry位置,如果找到了key相等的Entry,则会交换staleSlot元素的位置,且更新value值,然后进行过期Entry的清理工作,如下图:
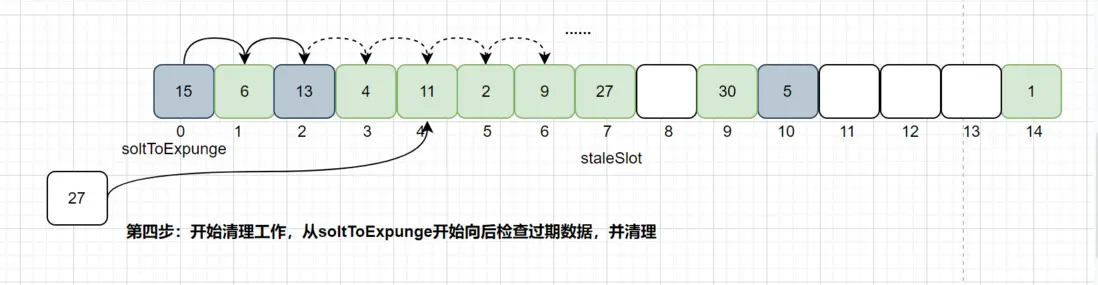
如果没有找到相等key的Entry的数据,如下图:
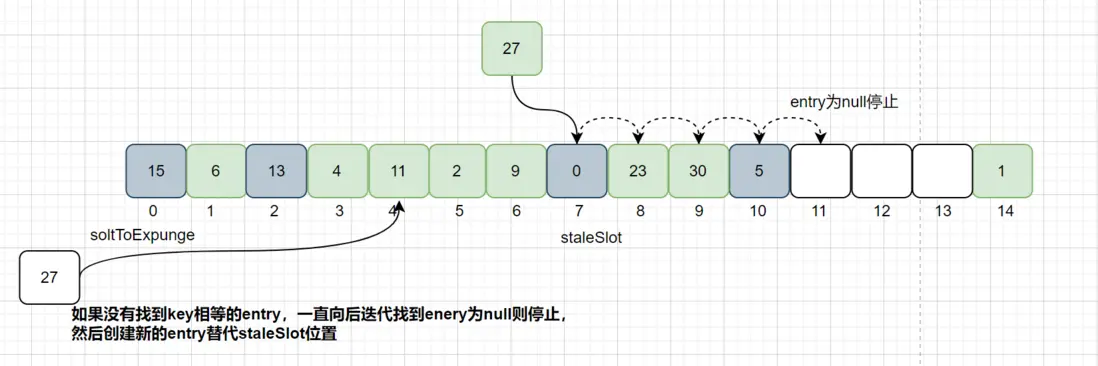
从当前节点staleSlot向后查找key值相等的Entry,如果没有找到,则会继续往后查找直到找到Entry为null停止,然后创建新的Entry,替换stableSlot的位置。
替换完成之后也是进行过期元素的清理工作,清理工作的方法主要有两个expungeStaleEntry和cleanSomeSlots。
private void set(ThreadLocal<?> key, Object value) {
// 获取Entry表
Entry[] tab = table;
// 获取表长度
int len = tab.length;
// 获取当前要放入元素的下标
int i = key.threadLocalHashCode & (len - 1);
// 循环查找
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]){
ThreadLocal<?> k = e.get();
// 如果查找到key相等的entry,则更新value
if (k == key) {
v.value = value;
return;
}
// 如果查找到为key为null的entry,说明key过期,被GC回收
// 这个时候要初始化探测式清理的起始位置
// 替换过期元素
if (k == null) {
replaceStateEntry(key, value, i);
return;
}
}
// 循环查找过程中,没有找到key相等的entry,且没有key过期的entry
// 则新建一个entry放入entry表中
table[i] = new Entry(key, value);
// 存放元素数量+1
int sz = ++size;
// 调用启发式清理, 且元素数量大于扩容阙值
// 则调用rehash方法,该方法会进行key过期的entry清理工作,清理完成之后再判断是否需要扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
上面代码流程主要如下:
- 首先获取Entry表,Entry表长度,通过hashCode计算下标,然后for循环Entry表。
- 如果循环查找过程中找到了key相等的Entry则更新value对应我们上面说的第二种情况。
- 如果循环查找过程找到了key为null的Entry,说明key过期了,替换过期元素,需要初始化探测式清理的其实位置,调用replaceStaleEntry()方法,这个方法我们下面再说,这个对应我们上面说的第四种情况。
- for循环查找完毕,说明在查找过程中该下标对应的Entry为null,则在新建一个Entry放入该槽位,然后调用启发式清理工作。
- 如果启发式清理未清理任务数据,且size超过扩容阙值(2/3),则调用rehash()方法,该方法会先进行一次探测式清理,清理过期元素,清理完毕之后如果size >= threshold - threshold / 4 ,则会进行扩容操作。
接下来看核心方法replaceStaleEntry(),该方法在查找过程中遇到key = null数据的时候会执行,该方法提供了替换过期数据的功能,可以对应上面说第四种情况来看,源码如下:
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
// 获取Entry表
Entry[] tab = table;
// 获取Entry表长度
int len = tab.length;
Entry e;
// 定义探测式清理起始位置 slotToExpunge = staleSlot
int slotToExpunge = staleSlot;
// 从staleSlot开始向前迭代查找是否有key=null的entry
// 如果有则更新slotToExpunge
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// staleSlot开始向后循环
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果查找到了key相等entry
// 则替换staleSlot和i的位置,且更新value的值
if (k == key) {
e.value = value;
// 替换staleSlot和i的位置
tab[i] = tab[staleSlot];
// 更新value值
tab[staleSlot] = e;
// 如果slotToExpunge == staleSlot,说明向前循环的没有查找到key过期的entry
// 更新slotToExpunge值
// 则会调用启动式过期清理,先会进行一遍过期元素探测操作
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果找到了key为null 且向前循环的没有查找到key过期的entry
// 则更新slotToExpunge
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 说明没有找到k == key的数据,且碰到Entry为null的数据
// 则将数据放入该槽位
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// slotToExpunge != staleSlot 说明从staleSlot开始向前迭代查找有key=null的entry
if (slotToExpunge != staleSlot)
// 启动式清理之前,先会进行一次过期元素探测,如果发现了有过期的数据就会先进行探测式清理
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
上面代码主要流程如下:
- 首先获取Entry表,Entry表长度,定义探测式清理起始位置 slotToExpunge = staleSlot。
- 从staleSlot开始向前迭代查找是否有key=null的entry,如果有则更新slotToExpunge。
- staleSlot开始向后循环,如果查找到了key相等entry,则替换staleSlot和i的位置,且更新value的值,然后判断slotToExpunge == staleSlot,说明向前循环的没有查找到key过期的entry, 然后更新slotToExpunge值,则会调用启动式过期清理,先会进行一遍过期元素探测操作,如果发现了有过期的数据就会先进行探测式清理。
- 如果找到了key为null 且向前循环的没有查找到key过期的entry,则更新slotToExpunge。
- 循环结束,方法没有退出,说明没有找到k == key的数据,且碰到Entry=null的数据,则将数据放入该槽位。
- 最后判断slotToExpunge != staleSlot,说明从staleSlot开始向前迭代查找有key=null的entry,则调用启动式清理,在启动式清理之前,先会进行一次过期元素探测,如果发现了有过期的数据就会先进行探测式清理。
ThreadLocalMap过期 key 的启发式清理流程
ThreadLocalMap两种过期key数据清理方式:探测式清理和启发式清理。
探测式清理
探测式清理方法expungeStaleEntry,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的Entry设置为null,遍历过程如果遇到未过期的数据则会将此数据rehash后重新在table数组中定位,如果定位的位置已经有了元素,则会将未过期的数据放在最靠近此位置的Entry = null的桶中,使rehash后的Entry数据距离正确的桶位置更近一点。这种优化会提高整个散列表查询性能。
// staleSlot探测式清理起始位置
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 将起始位置置空
tab[staleSlot].value = null;
tab[staleSlot] = null;
// 元素数量减1
size--;
// 重新迭代散列,直到发现空槽
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果key过期,则清空元素,数量减1
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
// 如果key没有过期,则重新计算hash,重新获取下标
int h = k.threadLocalHashCode & (len - 1);
// 如果当前下标存在值,则寻找离冲突key所在entry最近的空槽
if (h != i) {
// i位置槽置空
tab[i] = null;
// 寻找离冲突key所在entry最近的空槽,放入该槽
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
启发式清理
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len); // 从下一个位置开始
Entry e = tab[i];
// 遍历到key==null的Entry
if (e != null && e.get() == null) {
n = len; // 重置n
removed = true; // 标志有清理元素
i = expungeStaleEntry(i); // 清理
}
} while ( (n >>>= 1) != 0); // log(n) 限制--对数次
return removed;
}
从i的下一个位置判断元素是否需要清除,如果遇到key==null的元素则会重置n,需要清除且更新i的值,判断且清除完毕之后,n = n >>> 1直到n = 0则退出清理。
五、ThreadLocalMap.get()方法详解
主要包含两种情况,一种是hash计算出下标,该下标对应的Entry.key和我们传入的key相等的情况,另外一种就是不相等的情况。
相等情况:相等情况处理很简单,直接返回value,如下图:
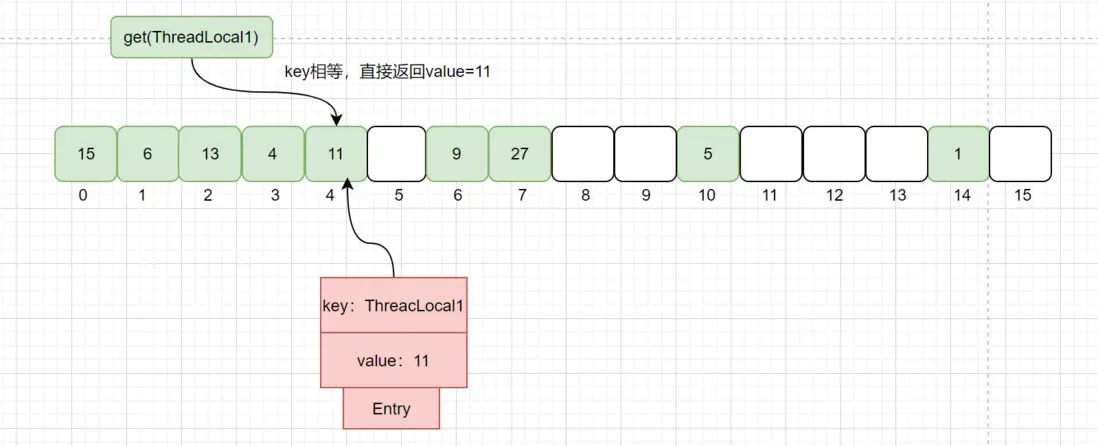
上图中比如get(ThreadLocal1)计算下标为4,且4存在Entry,且key相等,则直接返回value = 11。
不相等情况:
以get(ThreadLocal2)为例计算下标为4,且4存在Entry,但key相等,这个时候则为往后迭代寻找key相等的元素,如果寻找过程中发现了有key = null的元素则回进行探测式清理操作。如下图:
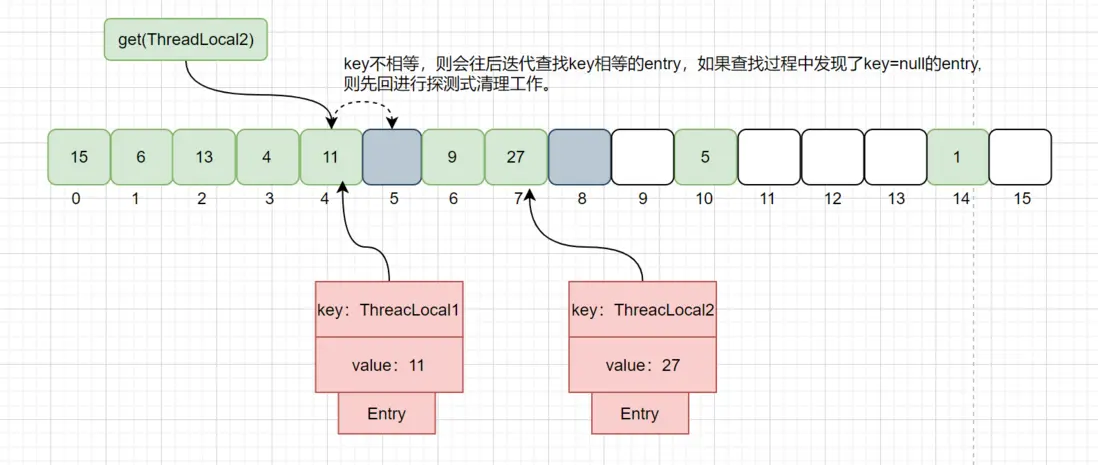
迭代到index=5的数据时,此时Entry.key=null,触发一次探测式数据回收操作,执行expungeStaleEntry()方法,执行完后,index 5,8的数据都会被回收,而index 6,7的数据都会前移,此时继续往后迭代,到index = 6的时候即找到了key值相等的Entry数据,如下图:
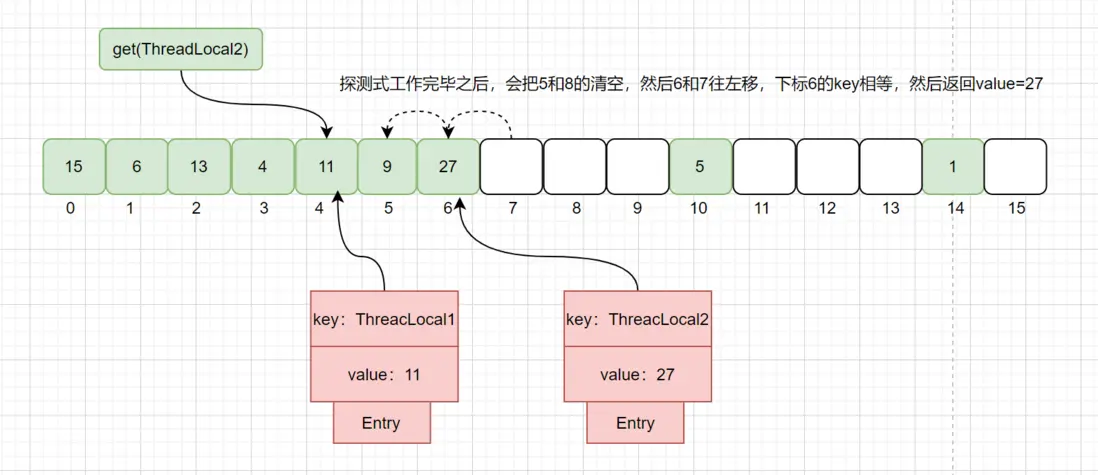
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 未找到的话,则调用setInitialValue()方法设置null
return setInitialValue();
}
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// key相等直接返回
if (e != null && e.get() == key)
return e;
else
// key不相等调用getEntryAfterMiss()方法
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 迭代往后查找key相等的entry
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
// 遇到key=null的entry,先进行探测式清理工作
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
ThreadLocalMap的扩容机制
在ThreadLocalMap.set()方法最后,如果执行完启发式清理工作之后,未清理任何数据,且当前散列数组中元素已经超过扩容阙值len*2/3,则执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
private void rehash() {
//先进行探测式清理工作
expungeStaleEntries();
//探测式清理完毕之后 如果size >= threshold - threshold / 4
// 也就是size >= threshold * 3/4,也就是 size >= len * 1/2,则扩容
if (size >= threshold - threshold / 4)
resize();
}
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
rehash()方法源码流程如下:
- 首先进行探测式清理工作
- 如果探测式清理工作完毕之后,如果size >= threshold - threshold / 4, 也就是size >= threshold * 3/4,也就是 size >= len * 1/2,则调用resize()扩容。
扩容方法resize()方法源码如下:
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
扩容方法执行之后tab的大小为原先的两倍oldLen * 2,然后变量老的散列表,重新计算hash位置,然后放到新的散列表中,如果出现hash冲突则往后寻找最近的entry为null的槽位放入,扩容完成之后,重新计算扩容阙值。
六、ThreadLocal.remove()方法源码详解
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 从hash获取的下标开始,寻找key相等的entry元素清除
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
ThreadLocal.remove()核心是调用ThreadLocalMap.remove()方法,流程如下:
- 通过hash计算下标。
- 从散列表该下标开始往后查key相等的元素,如果找到则做清除操作,引用置为null,GC的时候key就会置为null,然后执行探测式清理处理。
参考地址: ThreadLocal详解。