最佳实践-数据库的模糊搜索
一 常见场景
1.1 数据库表创建
首先创建一个学生表并添加姓名的普通索引。
CREATE TABLE `school`.`student` (
`id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int(3) NULL DEFAULT NULL,
`class_number` bigint(10) NULL DEFAULT NULL,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE,
INDEX `name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
并为其中填充几条数据:
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (1, '张三', 10, 3, '2023-07-20 09:31:29', '2023-07-20 09:31:34');
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (2, '李四', 11, 3, '2023-07-20 09:31:44', '2023-07-20 09:31:44');
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (3, '王五', 10, 3, '2023-07-20 09:32:19', '2023-07-20 09:32:19');
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (4, '盖伦', 9, 3, '2023-07-20 09:32:39', '2023-07-20 09:32:39');
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (5, '普朗克', 10, 3, '2023-07-20 09:32:56', '2023-07-20 09:32:56');
INSERT INTO `school`.`student` (`id`, `name`, `age`, `class_number`, `create_time`, `update_time`) VALUES (6, '卡特', 12, 3, '2023-07-20 09:34:31', '2023-07-20 09:34:31');
1.2 查询案例
假设现在有需要对name进行模糊查询,sql如下:
select * from student where name like '%王%';
1.3 案例分析
用EXPLAIN看看执行计划:

从图中发现是没有走索引的。那怎么办?索引岂不是白建了?
1.4 解决方法
别慌,先给你支一招,如下图:
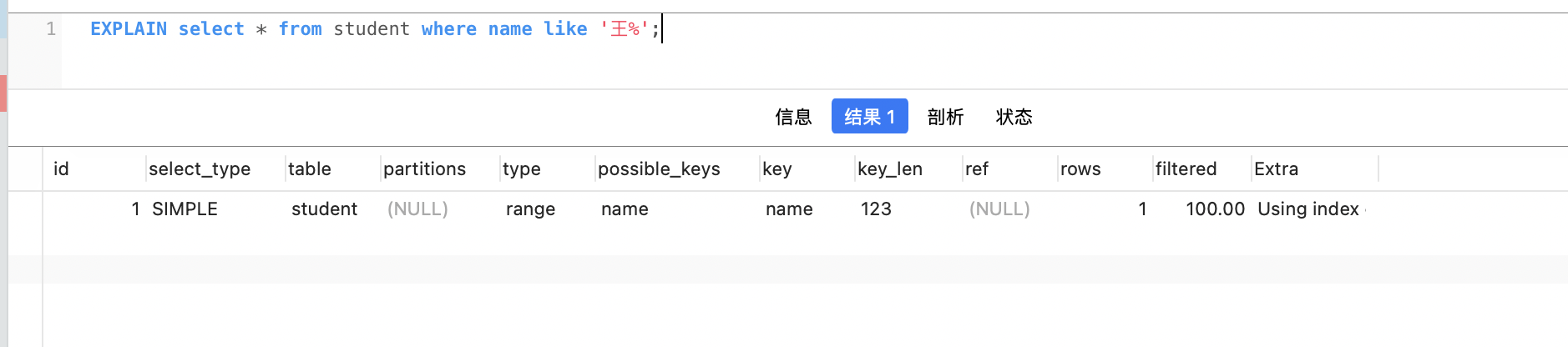
走最左侧原则,去掉左边的通配符,就可以发现能走索引了。
产品:我要的就是要全模糊,不要一边模糊搜索。
那该怎么办呢?
1.5 全文索引
这时候可以采用终极杀招,使用mysql 自带的全文索引。不懂全文索引的可以先去了解一下。简而言之能实现我们全模糊的要求还走索引,是一种空间换时间的典型。
create fulltext index name_fulltext on student(name) WITH PARSER ngram;;
首先建立一个name的全文索引。
接着采用全文索引提供的布尔查询(也可以在查询参数上加通配符*):
select * from student where match(name) against('朗' IN BOOLEAN MODE);
select * from student where MATCH ( name ) against ( '王' IN NATURAL LANGUAGE MODE );
发现,结果啥也没有。什么情况?
这个问题有很多原因,其中最常见的就是最小搜索长度导致的。
MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。
这两个的默认值可以使用以下命令查看
show variables like '%ft%';
可以看到这两个变量在 MyISAM 和 InnoDB 两种存储引擎下的变量名和默认值
// MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
// InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;
可以看到最小搜索长度 MyISAM 引擎下默认是 4,InnoDB 引擎下是 3,也即,MySQL 的全文索引只会对长度大于等于 4 或者 3 的词语建立索引,而刚刚搜索的长度大于等于 4。
配置最小搜索长度
全文索引的相关参数都无法进行动态修改,必须通过修改 MySQL 的配置文件来完成。修改最小搜索长度的值为 1,首先打开 MySQL 的配置文件 /etc/my.cnf,在 [mysqld] 的下面追加以下内容
[mysqld]
innodb_ft_min_token_size = 1
ft_min_word_len = 1
可以使用以下命令查询配置文件路径
mysql --help|grep 'my.cnf'
然后重启 MySQL 服务器,并修复全文索引。
⚠️注意,修改完参数以后,一定要修复下索引,不然参数不会生效。
两种方式,一种是重建索引,一种是执行命令。
repair table student quick;
MySQL 的全文索引最开始仅支持英语,因为英语的词与词之间有空格,使用空格作为分词的分隔符是很方便的。亚洲文字,比如汉语、日语、汉语等,是没有空格的,这就造成了一定的限制。不过 MySQL 5.7.6 开始,引入了一个 ngram 全文分析器来解决这个问题,并且对 MyISAM 和 InnoDB 引擎都有效。

再次执行执行计划,可以看到现在是走索引了。
1.6 ElasticSearch
还有一个执行效率更高更快的办法,那就是引入ES。这里不过多介绍,大概方案就是,用text类型对需要模糊查询对词进行分词,其次是利用match查询进行模糊查询。要达到模糊的效果,首先是要对中英文采取不同对分词器,然后利用match的Operator.AND熟悉进行查询。
Operator.AND和Operator.OR是用于设置match查询的操作符的枚举类型。它们的区别在于如何处理多个查询词的匹配逻辑:
Operator.AND:使用AND操作符,表示所有的查询词都必须出现在匹配的文档中。只有当文档中同时包含所有的查询词时,才会被匹配到。
Operator.OR:使用OR操作符,表示只要文档中包含任何一个查询词,就会被匹配到。只要文档中包含至少一个查询词,就会被视为匹配。
具体案例为:
{
"from": 0,
"size": 20,
"timeout": "60s",
"query": {
"bool": {
"must": [
{
"exists": {
"field": "yb_code",
"boost": 1
}
},
{
"match": {
"name": {
"query": "高血压",
"operator": "AND",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1
}
}
}
],
"filter": [
{
"bool": {
"must": [
{
"term": {
"category": {
"value": 1,
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"sort": [
{
"name_length": {
"order": "asc"
}
},
{
"id": {
"order": "asc"
}
}
]
}
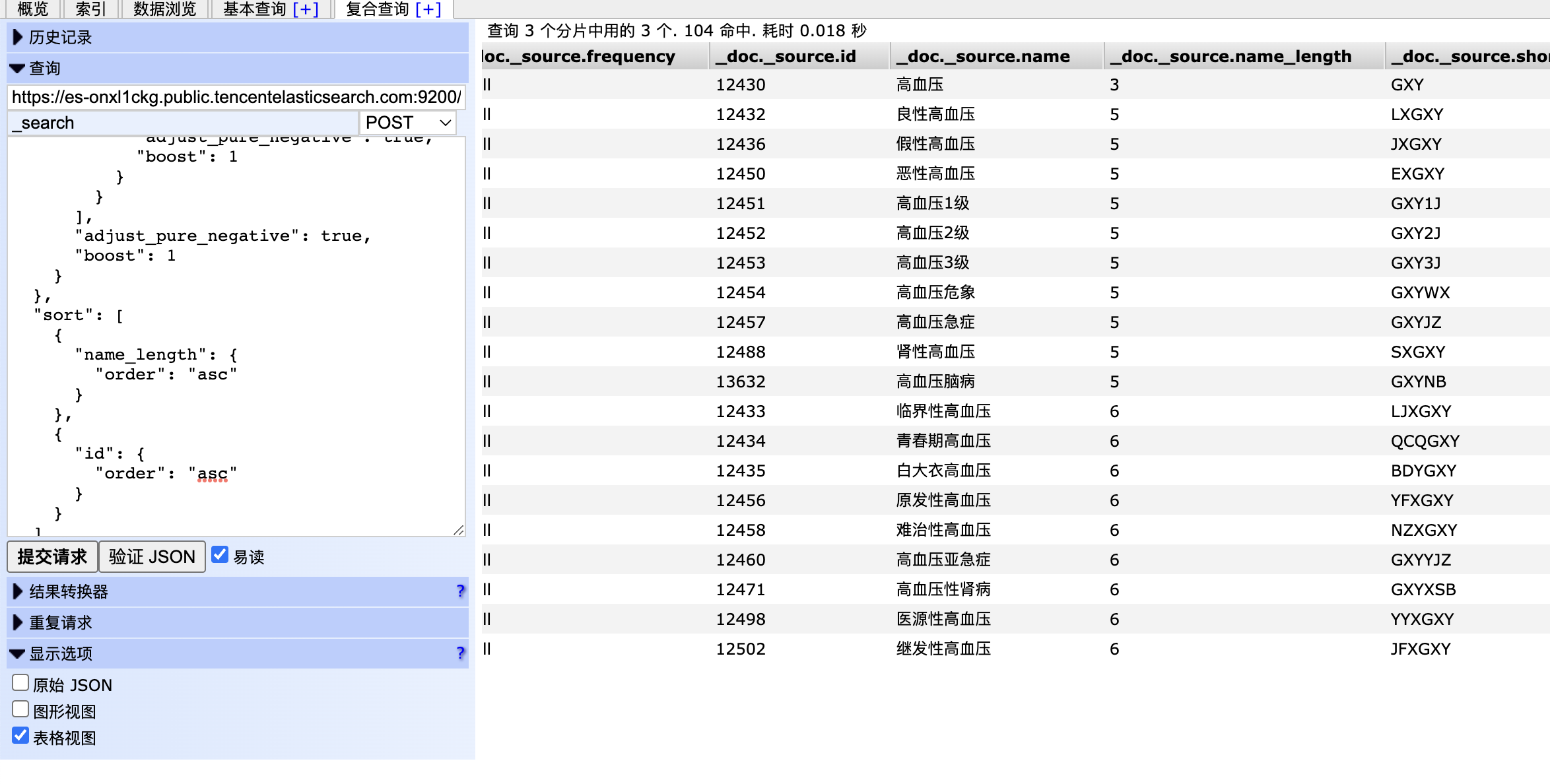
其中match可以用matchPhrase,但是效果没有match好,或者使用wildcardQuery这种通配符查询的方式也可以。
PS:
如果想看某个字段分词情况,可以用下面的请求:
GET https://{ip}:{port}/index/_doc/{id}/_termvectors?fields={field}