JAVA并发(一)
1、锁机
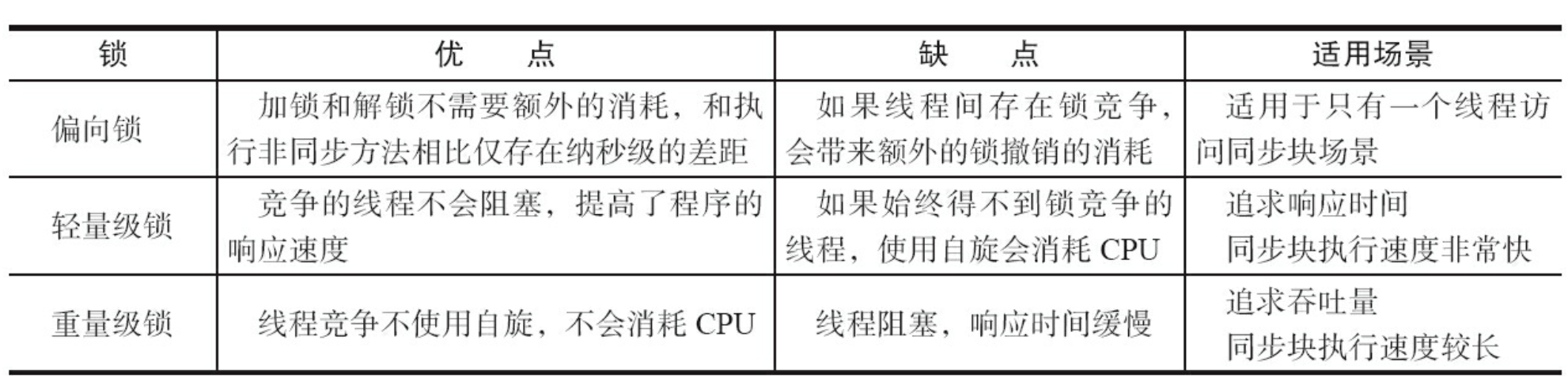
1.1 锁的升级与对比
为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状 态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏 向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高 获得锁和释放锁的效率
1.1.1 偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同 一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并 获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出 同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word(存储对象的hashcode和锁信息)里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需 要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则 使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
(1)偏向锁的撤销
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时, 持有偏向锁的线程才会释放锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正 在执行的字节码)。它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着, 如果线程不处于活动状态,则将对象头设置成无锁状态;如果线程仍然活着,拥有偏向锁的栈 会被执行,遍历偏向对象的锁记录,栈中的锁记录和对象头的Mark Word要么重新偏向于其他 线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。
1.1.2 轻量级锁
(1)轻量级锁加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用 CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
(2)轻量级锁解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成 功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级 成重量级锁,就不会再恢复到轻量级锁状态。当锁处于这个状态下,其他线程试图获取锁时, 都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮 的夺锁之争。
1.1.3 锁的优缺点对比
1.2 原子操作的实现原理
原子(atomic)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意 为“不可被中断的一个或一系列操作”。在多处理器上实现原子操作就变得有点复杂。
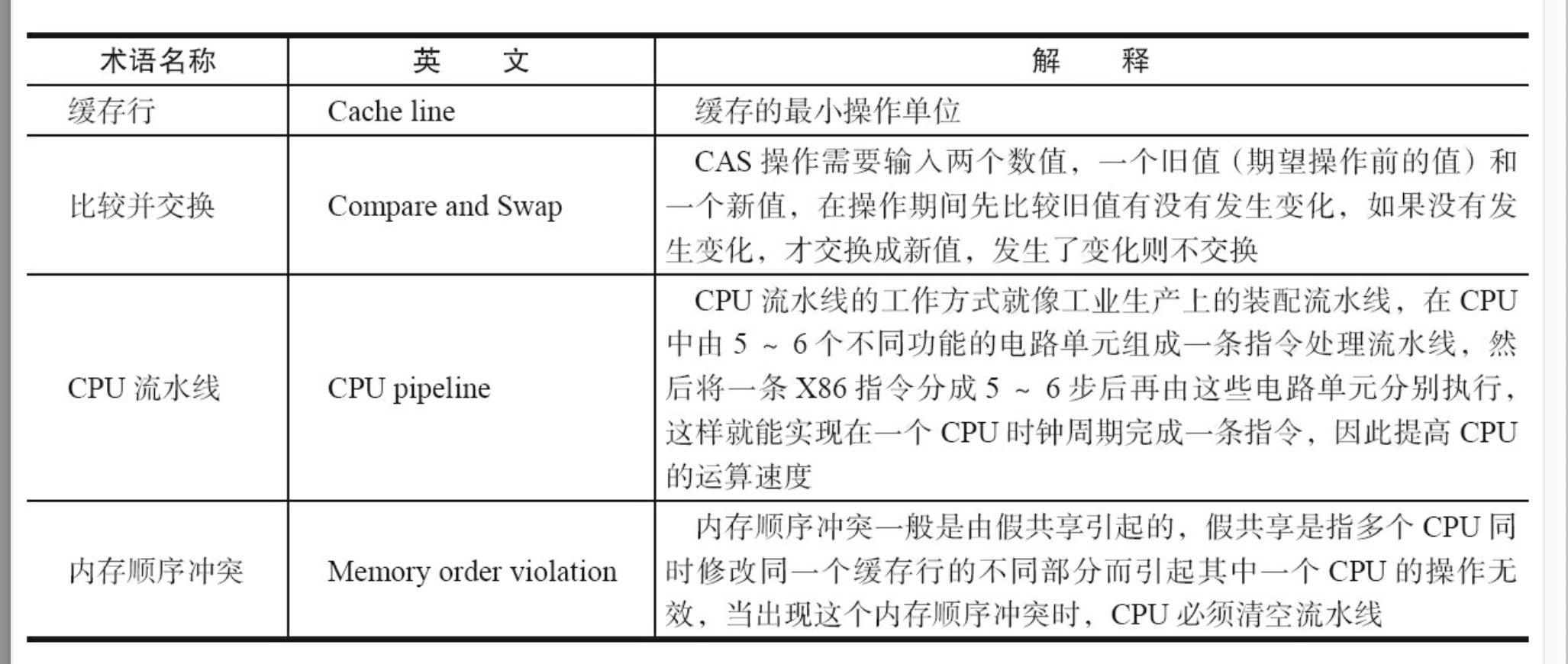
1.2.1 在Java中可以通过锁和循环CAS的方式来实现原子操作。
JVM中的CAS操作正是利用了处理器提供的CMPXCHG指令实现的。自旋CAS实现的基本 思路就是循环进行CAS操作直到成功为止,以下代码实现了一个基于CAS线程安全的计数器 方法safeCount和一个非线程安全的计数器count。
package com.curr;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 并发计数器demo
* @author likecat
* @version 1.0
* @date 2022/7/7 17:08
*/
public class CurrDemo {
private AtomicInteger atomicI = new AtomicInteger(0);
private int i = 0;
public static void main(String[] args) {
final CurrDemo cas = new CurrDemo();
List<Thread> ts = new ArrayList<Thread>(600);
long start = System.currentTimeMillis();
for (int j = 0; j < 100; j++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
cas.count();
cas.safeCount();
}
}
});
ts.add(t);
}
for (Thread t : ts) {
t.start();
}
// 等待所有线程执行完成
for (Thread t : ts) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(cas.i);
System.out.println(cas.atomicI.get());
System.out.println(System.currentTimeMillis() - start);
}
/**
* 使用CAS实现线程安全计数器
*
*/
private void safeCount() {
for (;;) {
int i = atomicI.get();
boolean suc = atomicI.compareAndSet(i, ++i);
if (suc) {
break;
}
}
}
/**
* 非线程安全计数器
*/
private void count() {
i++;
}
}
从Java 1.5开始,JDK的并发包里提供了一些类来支持原子操作,如AtomicBoolean(用原子 方式更新的boolean值)、AtomicInteger(用原子方式更新的int值)和AtomicLong(用原子方式更 新的long值)。这些原子包装类还提供了有用的工具方法,比如以原子的方式将当前值自增1和 自减1。
1.2.2 CAS实现原子操作的三大问题
在Java并发包中有一些并发框架也使用了自旋CAS的方式来实现原子操作,比如 LinkedTransferQueue类的Xfer方法。CAS虽然很高效地解决了原子操作,但是CAS仍然存在三 大问题。ABA问题,循环时间长开销大,以及只能保证一个共享变量的原子操作。
- ABA问题。因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化 则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它 的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面 追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成1A→2B→3A。从 Java 1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个 类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是 否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
- 循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。pause指令有两个作用:第一,它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;第二,它可以避免在退出循环的时候因内存顺序冲突(Memory Order Violation)而引起CPU流水线被清空(CPU Pipeline Flush),从而提高CPU的执行效率。
- 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。。还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
1.2.3 使用锁机制实现原子操作
锁机制保证了只有获得锁的线程才能够操作锁定的内存区域。JVM内部实现了很多种锁机制,有偏向锁、轻量级锁和互斥锁。有意思的是除了偏向锁,JVM实现锁的方式都用了循环CAS,即当一个线程想进入同步块的时候使用循环CAS的方式来获取锁,当它退出同步块的时候使用循环CAS释放锁。
2 Java内存模型
2.1 Java内存模型的基础
2.1.1 并发编程模型的两个关键问题
在并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体)。通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递
在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信。
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
2.1.2 Java内存模型的抽象结构
在Java中,所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享局部变量(Local Variables),方法定义参数(Java语言规范称之为Formal Method Parameters)和异常处理器参数(ExceptionHandler Parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
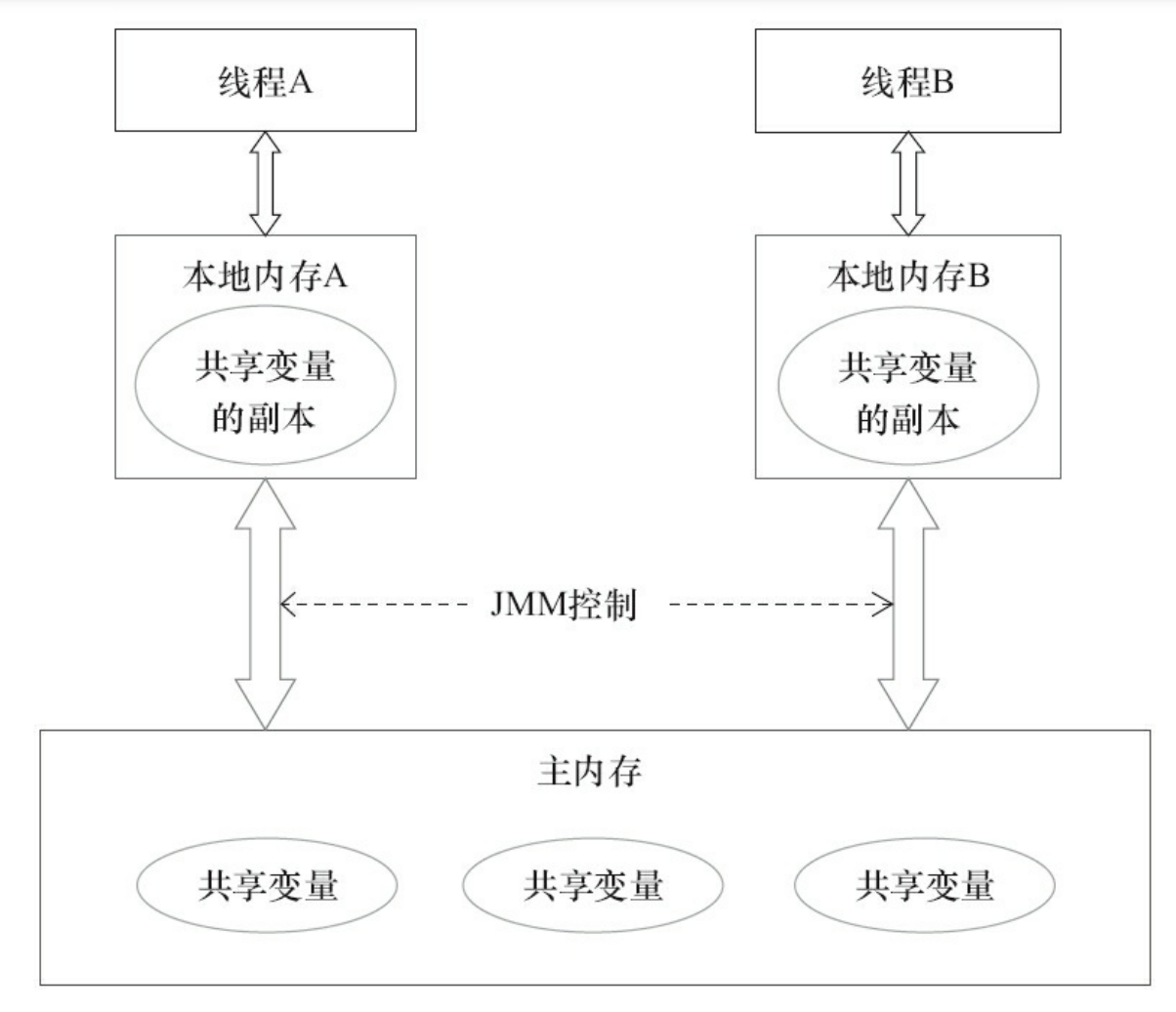
从上图来看,如果线程A与线程B之间要通信的话,必须要经历下面2个步骤。
1)线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2)线程B到主内存中去读取线程A之前已更新过的共享变量。
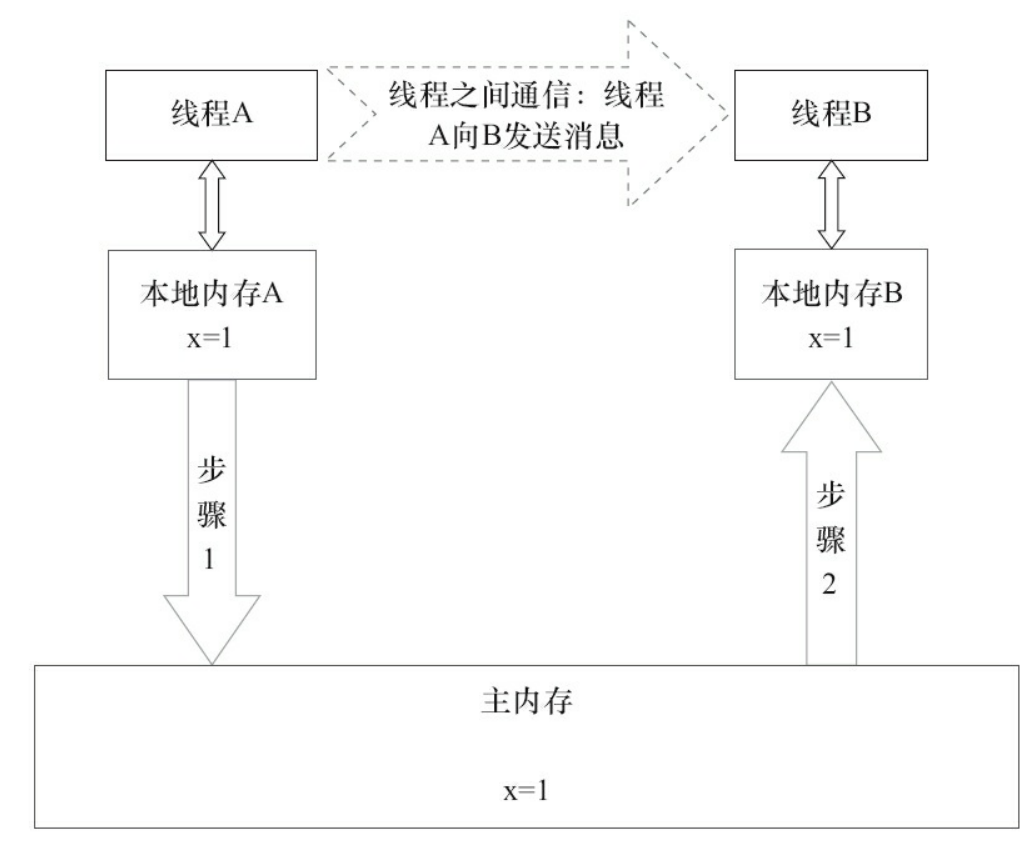
如上图所示,本地内存A和本地内存B由主内存中共享变量x的副本。假设初始时,这3个内存中的x值都为0。线程A在执行时,把更新后的x值(假设值为1)临时存放在自己的本地内存A中。当线程A和线程B需要通信时,线程A首先会把自己本地内存中修改后的x值刷新到主内存中,此时主内存中的x值变为了1。随后,线程B到主内存中去读取线程A更新后的x值,此时线程B的本地内存的x值也变为了1。
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为Java程序员提供内存可见性保证。
2.1.3 从源代码到指令序列的重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,
源代码 -> 1:编译器优化重排序 -> 2:指令级并行重排序 -> 3:内存系统重排序 -> 最终执行的指令序列
上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
2.1.4 并发编程模型的分类
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!
2..2 重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
2.2.1 数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列3种类型

上面3种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
2.2.2 as-if-serial语义
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。asif-serial语义使单程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
2.2.3 程序顺序规则
根据happens-before的程序顺序规则,上面计算圆的面积的示例代码存在3个happensbefore关系。
1)A happens-before B。
2)B happens-before C。
3)A happens-before C。
这里的第3个happens-before关系,是根据happens-before的传递性推导出来的。
这里A happens-before B,但实际执行时B却可以排在A之前执行(看上面的重排序后的执行顺序)。如果A happens-before B,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens-before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法(notillegal),JMM允许这种重排序。
在不改变程序执行结果的前提下,尽可能提高并行度。
2.2.4 重排序对多线程的影响
重排序是否会改变多线程程序的执行结果。请看下面的示例代码。
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
……
}
}
}
flag变量是个标记,用来标识变量a是否已被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
操作1和操作2做了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还没有被线程A写入,在这里多线程程序的语义被重排序破坏了!
在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(Reorder Buffer,ROB)的硬件缓存中。当操作3的条件判断为真时,就把该计算结果写入变量i中。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
2.3 顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺序一致性内存模型作为参照。
2.3.1 数据竞争与顺序一致性
当程序未正确同步时,就可能会存在数据竞争。Java内存模型规范对数据竞争的定义如
下。
在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。JMM对正确同步的多线程程序的内存一致性做了如下保证。
如果程序是正确同步的,程序的执行将具有顺序一致性(Sequentially Consistent)——即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同。这里的同步是指广义上的同步,包括对常用同步原语(synchronized、volatile和final)的正确使用
2.3.2 顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性。
- 1)一个线程中的所有操作必须按照程序的顺序来执行。
- 2)(不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
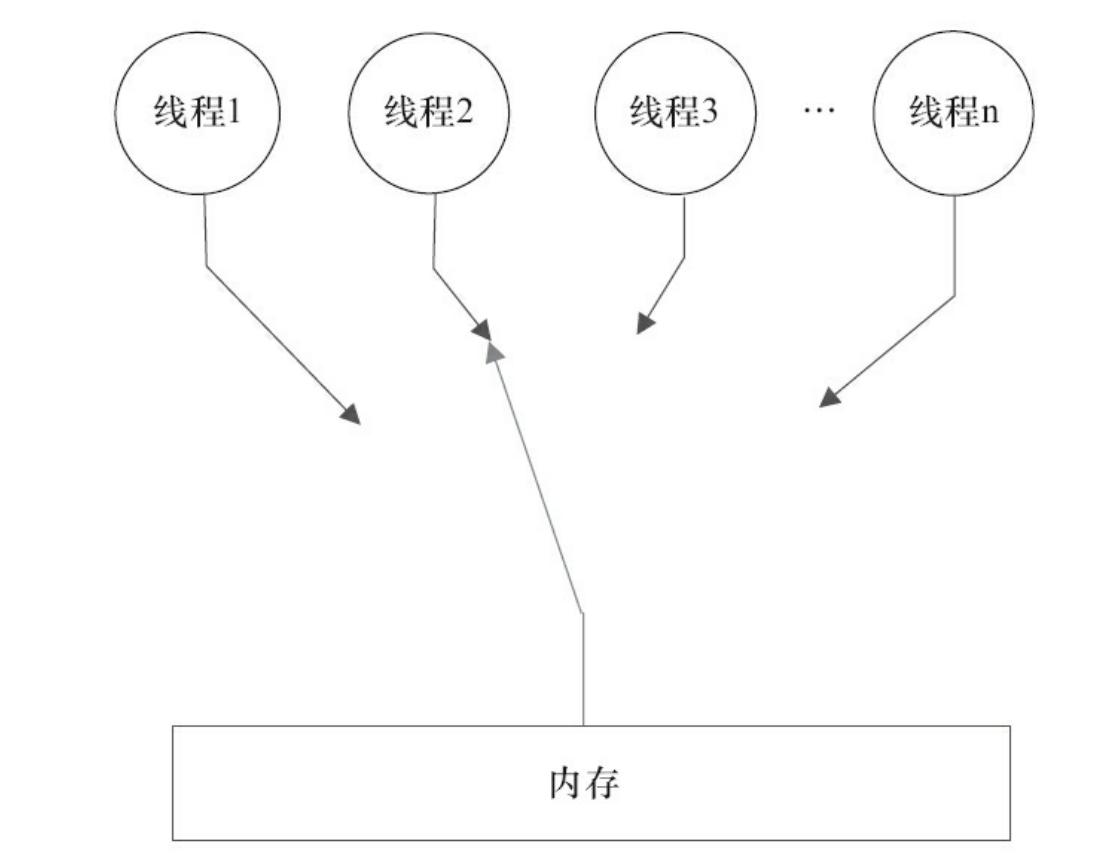
在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程,同时每一个线程必须按照程序的顺序来执行内存读/写操作。在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读/写操作串行化(即在顺序一致性模型中,所有操作之间具有全序关系)。
为了更好进行理解,假设有两个线程A和B并发执行。其中A线程有3个操作,它们在程序中的顺序是:
A1→A2→A3。B线程也有3个操作,它们在程序中的顺序是:B1→B2→B3。
假设这两个线程使用监视器锁来正确同步:A线程的3个操作执行后释放监视器锁,随后B
线程获取同一个监视器锁。那么程序在顺序一致性模型中的执行效果将会是:
A1→A2→A3→B1→B2→B3
现在我们再假设这两个线程没有做同步,那这个未同步程序在顺序一致性模型中的执行示意图可能是:
B1→A1→A2→B2→A3→B3
未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。线程A和B看到的执行顺序可能都是:B1→A1→A2→B2→A3→B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操作必须立即对任意线程可见。
但是,在JMM中就没有这个保证。未同步程序在JMM中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,在没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其他线程看到的操作执行顺序将不一致。
2.3.3 同步程序的顺序一致性效果
下面,对前面的示例程序ReorderExample用锁来同步,看看正确同步的程序如何具有顺序
一致性。
请看下面的示例代码。
class ReorderExample {
int a = 0;
boolean flag = false;
public synchronized void writer() { // 获取锁
a = 1; // 1
flag = true; // 2
} // 释放锁
public synchronized void reader() { // 获取锁
if (flag) { // 3
int i = a * a; // 4
……
}
} // 释放锁
}
在上面示例代码中,假设A线程执行writer()方法后,B线程执行reader()方法。这是一个正确同步的多线程程序。根据JMM规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。
顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在JMM中,临界区内的代码可以重排序(但JMM不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM会在退出临界区和进入临界区这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图。虽然线程A在临界区内做了重排序,但由于监视器互斥执行的特性,这里的线程B根本无法“观察”到线程A在临
界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
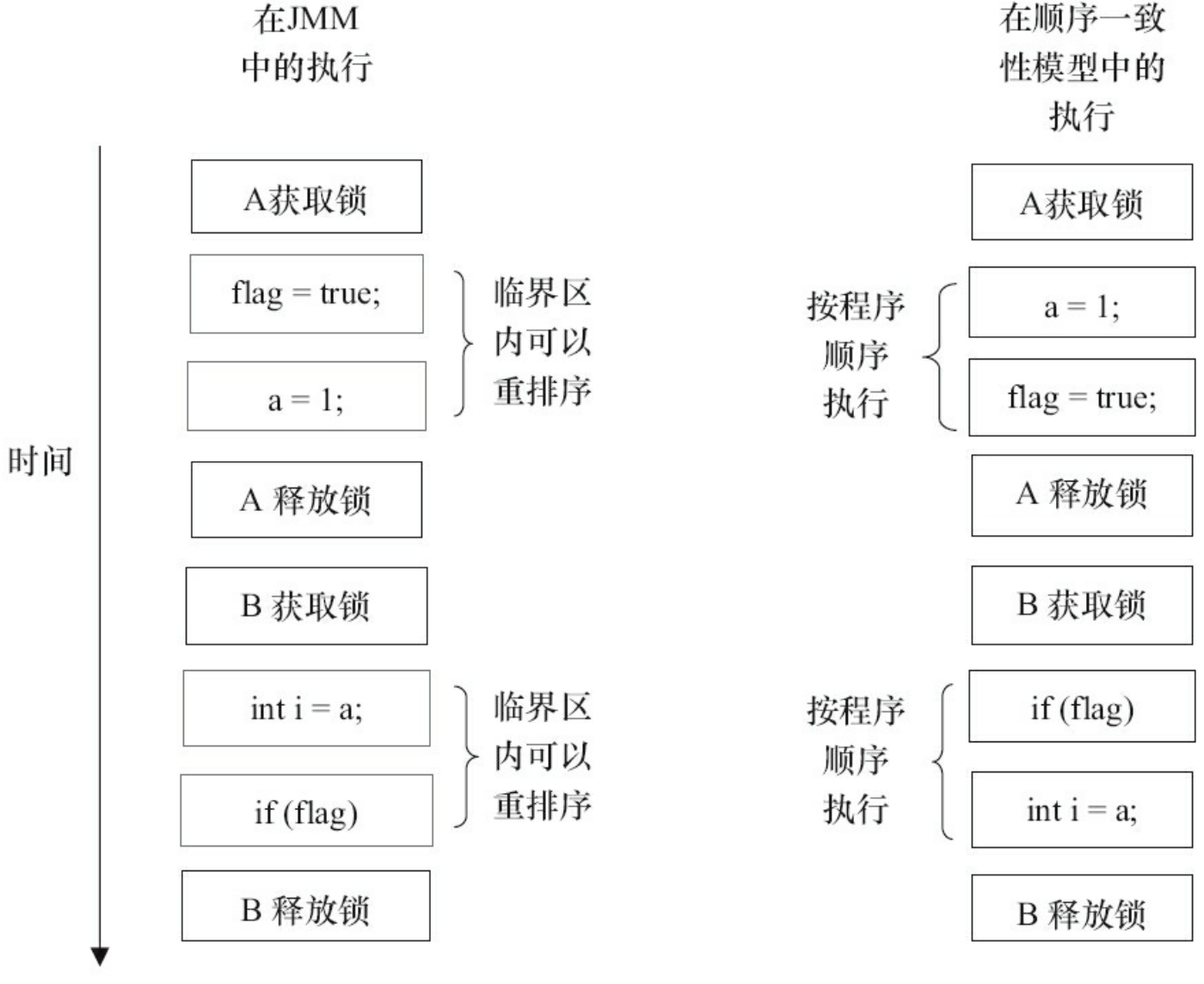
JMM在具体实现上的基本方针为:在不改变(正确同步的)程序执行结果的前提下,尽可能地为编译器和处理器的优化打开方便之门。
2.3.4 未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM只提供最小安全性:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,Null,False),JMM保证线程读操作读取到的值不会无中生有(Out Of Thin Air)的冒出来。为了实现最小安全性,JVM在堆上分配对象时,首先会对内存空间进行清零,然后才会在上面分配对象(JVM内部会同步这两个操作)。因此,在已清零的内存空间(Pre-zeroed Memory)分配对象时,域的默认初始化已经完成了。
JMM不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为如果想要保证执行结果一致,JMM需要禁止大量的处理器和编译器的优化,这对程序的执行性能会产生很大的影响。而且未同步程序在顺序一致性模型中执行时,整体是无序的,其执行结果往往无法预知。而且,保证未同步程序在这两个模型中的执行结果一致没什么意义。
未同步程序在JMM中的执行时,整体上是无序的,其执行结果无法预知。未同步程序在两个模型中的执行特性有如下几个差异。
1)顺序一致性模型保证单线程内的操作会按程序的顺序执行,而JMM不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。
2)顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而JMM不保证所有线程能看到一致的操作执行顺序。
3)JMM不保证对64位的long型和double型变量的写操作具有原子性,而顺序一致性模型保证对所有的内存读/写操作都具有原子性。
第3个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(Bus Transaction)。总线事务包括读事务(Read Transaction)和写事务(Write Transaction)。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读/写内存中一个或多个物理上连续的字。在一个处理器执行总线事务期间,总线会禁止其他的处理器和I/O设备执行内存的读/写。
在一些32位的处理器上,如果要求对64位数据的写操作具有原子性,会有比较大的开销。为了照顾这种处理器,Java语言规范鼓励但不强求JVM对64位的long型变量和double型变量的写操作具有原子性。当JVM在这种处理器上运行时,可能会把一个64位long/double型变量的写操作拆分为两个32位的写操作来执行。这两个32位的写操作可能会被分配到不同的总线事务中执行,此时对这个64位变量的写操作将不具有原子性。
2.4 volatile的内存语义
当声明共享变量为volatile后,对这个变量的读/写将会很特别。
2.4.1 volatile的特性
理解volatile特性的一个好方法是把对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步。
class VolatileFeaturesExample {
volatile long vl = 0L; // 使用volatile声明64位的long型变量
public void set(long l) {
vl = l; // 单个volatile变量的写
}
public void getAndIncrement () {
vl++; // 复合(多个)volatile变量的读/写
}
public long get() {
return vl; // 单个volatile变量的读
}
}
锁的happens-before规则保证释放锁和获取锁的两个线程之间的内存可见性,这意味着对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。锁的语义决定了临界区代码的执行具有原子性。这意味着,即使是64位的long型和double型变量,只要它是volatile变量,对该变量的读/写就具有原子性。如果是多个volatile操作或类似于volatile++这种复合操作,这些操作整体上不具有原子性。
简而言之,volatile变量自身具有下列特性。
-
可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
-
原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
2.4.2 volatile写-读建立的happens-before关系
volatile对线程的内存可见性的影响比volatile自身的特性更为重要
从JSR-133开始(即从JDK5开始),volatile变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile的写-读与锁的释放-获取有相同的内存效果:volatile写和锁的释放有相同的内存语义;volatile读与锁的获取有相同的内存语义。
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a; // 4
……
}
}
}
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens-before规则,这个过程建立的happens-before关系可以分为3类:
1)根据程序次序规则,1 happens-before 2;3 happens-before 4。
2)根据volatile规则,2 happens-before 3。
3)根据happens-before的传递性规则,1 happens-before 4。
这里A线程写一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,将立即变得对B线程可见。
2.4.3 volatile写-读的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
以上面示例程序VolatileExample为例,假设线程A首先执行writer()方法,随后线程B执行reader()方法,初始时两个线程的本地内存中的flag和a都是初始状态。线程A在写flag变量后,本地内存A中被线程A更新过的两个共享变量的值被刷新到主内存中。此时,本地内存A和主内存中的共享变量的值是一致的。
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
在读flag变量后,本地内存B包含的值已经被置为无效。此时,线程B必须从主内存中读取共享变量。线程B的读取操作将导致本地内存B与主内存中的共享变量的值变成一致。
下面对volatile写和volatile读的内存语义做个总结。
-
线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
-
线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
-
线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
2.4.4 volatile内存语义的实现
为了实现volatile内存语义,JMM会分别限制编译器重排序和处理器重排序。
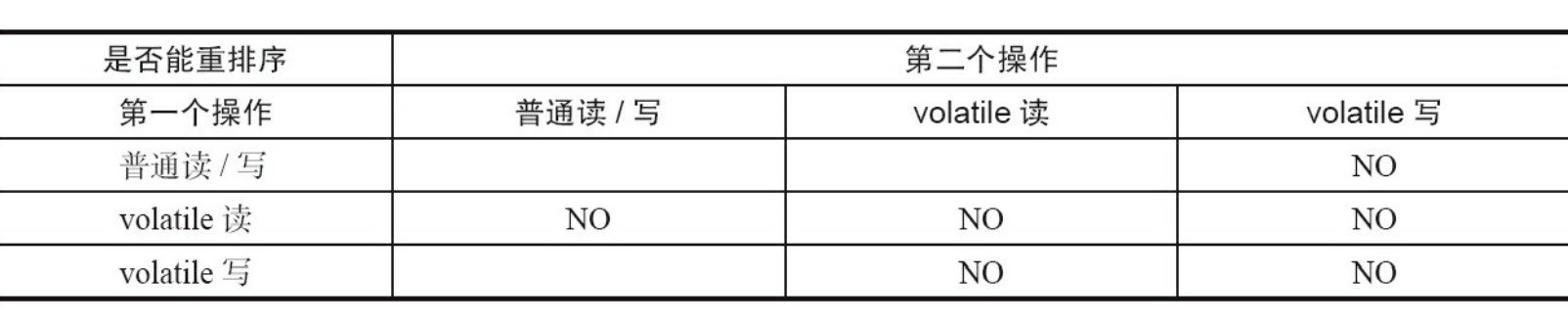
举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
我们可以从上图看出。
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略。
1、在每个volatile写操作的前面插入一个StoreStore屏障。
2、在每个volatile写操作的后面插入一个StoreLoad屏障。
3、在每个volatile读操作的后面插入一个LoadLoad屏障。
4、在每个volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
(StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。StoreLoad屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。)
X86处理器仅会对写-读操作做重排序。X86不会对读-读、读-写和写-写操作做重排序,因此在X86处理器中会省略掉这3种操作类型对应的内存屏障。在X86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在X86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
2.4.5 JSR-133为什么要增强volatile的内存语义
2.5 锁的内存语义
锁可以让临界区互斥执行
2.5.1 锁的释放-获取建立的happens-before关系
锁是Java并发编程中最重要的同步机制。锁除了让临界区互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
class MonitorExample {
int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
……
} // 6
}
假设线程A执行writer()方法,随后线程B执行reader()方法。根据happens-before规则,这个过程包含的happens-before关系可以分为3类。
1)根据程序次序规则,1 happens-before 2,2 happens-before 3;4 happens-before 5,5 happensbefore 6。
2)根据监视器锁规则,3 happens-before 4。
3)根据happens-before的传递性,2 happens-before 5。
示在线程A释放了锁之后,随后线程B获取同一个锁。2 happens-before5。因此,线程A在释放锁之前所有可见的共享变量,在线程B获取同一个锁之后,将立刻变得对B线程可见。
2.5.2 锁的释放和获取的内存语义
当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。
当线程获取锁时,JMM会把该线程对应的本地内存置为无效。从而使得被监视器保护的临界区代码必须从主内存中读取共享变量。
对比锁释放-获取的内存语义与volatile写-读的内存语义可以看出:锁释放与volatile写有相同的内存语义;锁获取与volatile读有相同的内存语义。
下面对锁释放和锁获取的内存语义做个总结。
-
线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A
对共享变量所做修改的)消息。 -
线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共
享变量所做修改的)消息。 -
线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发
送消息。
2.5.3 锁内存语义的实现
借助ReentrantLock的源代码,来分析锁内存语义的具体实现机制。
class ReentrantLockExample {
int a = 0;
ReentrantLock lock = new ReentrantLock();
public void writer() {
lock.lock(); // 获取锁
try {
a++;
} f inally {
lock.unlock(); // 释放锁
}
}
public void reader () {
lock.lock(); // 获取锁
try {
int i = a;
……
} f inally {
lock.unlock(); // 释放锁
}
}
}
在ReentrantLock中,调用lock()方法获取锁;调用unlock()方法释放锁。ReentrantLock的实现依赖于Java同步器框架AbstractQueuedSynchronizer(简称之为AQS)。AQS使用一个整型的volatile变量(命名为state)来维护同步状态。
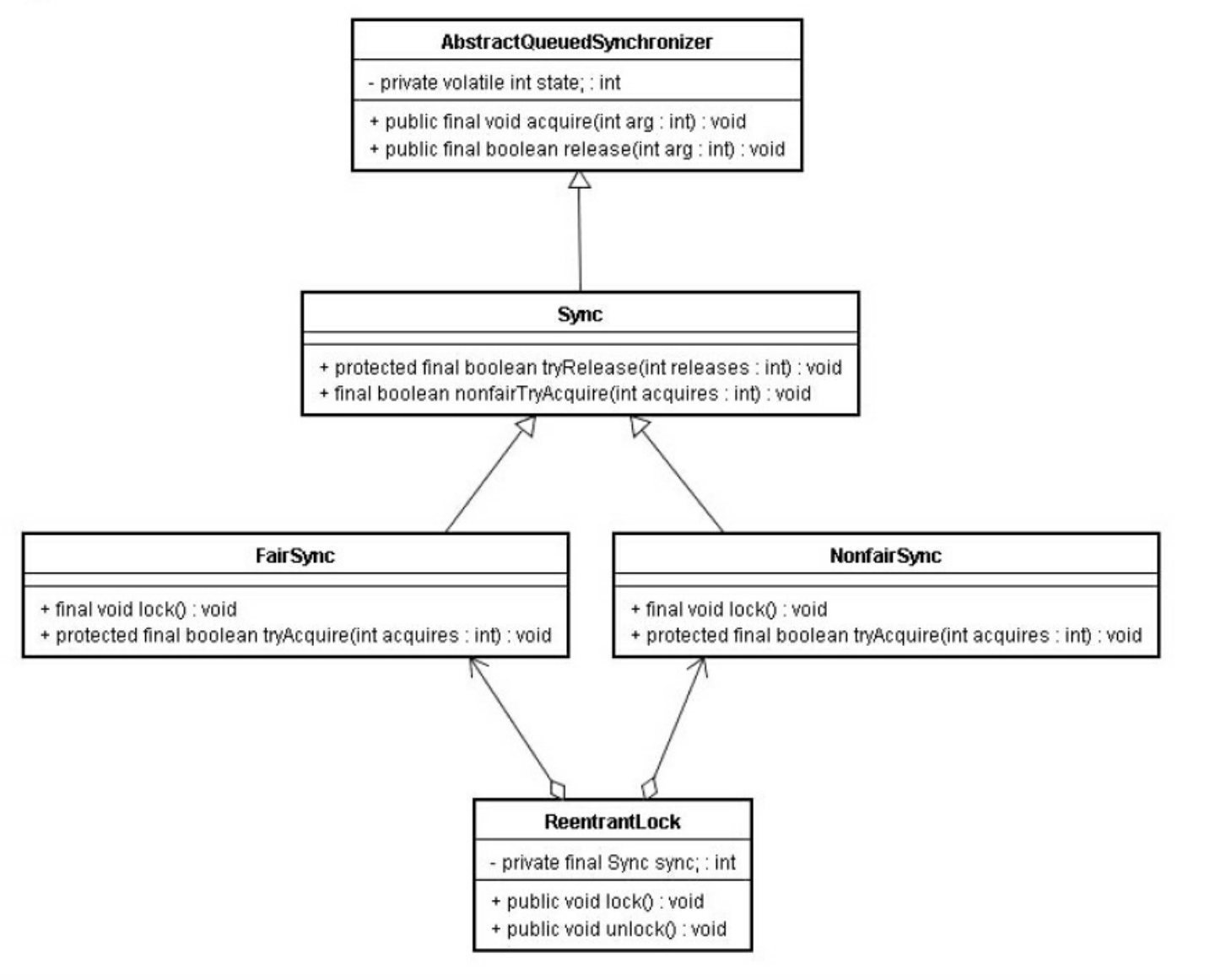
ReentrantLock分为公平锁和非公平锁,我们首先分析公平锁。
使用公平锁时,加锁方法lock()调用轨迹如下。
1)ReentrantLock:lock()。
2)FairSync:lock()。
3)AbstractQueuedSynchronizer:acquire(int arg)。
4)ReentrantLock:tryAcquire(int acquires)。
在第4步真正开始加锁,下面是该方法的源代码。
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread(); //获取当前执行线程
int c = getState(); // 获取锁的开始,首先读volatile变量state
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
从上面源代码中我们可以看出,加锁方法首先读volatile变量state。
在使用公平锁时,解锁方法unlock()调用轨迹如下。
1)ReentrantLock:unlock()。
2)AbstractQueuedSynchronizer:release(int arg)。
3)Sync:tryRelease(int releases)。
在第3步真正开始释放锁,下面是该方法的源代码。
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c); // 释放锁的最后,写volatile变量state
return free;
}
公平锁在释放锁的最后写volatile变量state,在获取锁时首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见。
现在我们来分析非公平锁的内存语义的实现。非公平锁的释放和公平锁完全一样,所以这里仅仅分析非公平锁的获取。使用非公平锁时,加锁方法lock()调用轨迹如下。
1)ReentrantLock:lock()。
2)NonfairSync:lock()。
3)AbstractQueuedSynchronizer:compareAndSetState(int expect,int update)。
在第3步真正开始加锁,下面是该方法的源代码。
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
该方法以原子操作的方式更新state变量,
compareAndSet()(CAS):如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。此操作具有volatile读和写的内存语义。
我们分别从编译器和处理器的角度来分析,CAS如何同时具有volatile读和volatile写的内存语义。
前文我们提到过,编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。组合这两个条件,意味着为了同时实现volatile读和volatile写的内存语义,编译器不能对CAS与CAS前面和后面的任意内存操作重排序。
sun.misc.Unsafe类的compareAndSwapInt()方法的源代码。
public final native boolean compareAndSwapInt(Object o, long offset,
int expected, int x);
可以看到,这是一个本地方法调用。程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前
缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(Lock Cmpxchg)。反之,如
果程序是在单处理器上运行,就省略lock前缀。
对lock前缀的说明如下。
1)确保对内存的读-改-写操作原子执行。在Pentium及Pentium之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从Pentium 4、Intel Xeon及P6处理器开始,Intel使用缓存锁定(Cache Locking)来保证指令执行的原子性。缓存锁定将大大降低lock前缀指令的执行开销。
2)禁止该指令,与之前和之后的读和写指令重排序。
3)把写缓冲区中的所有数据刷新到内存中。
上面的第2点和第3点所具有的内存屏障效果,足以同时实现volatile读和volatile写的内存语义。
现在对公平锁和非公平锁的内存语义做个总结。
- 公平锁和非公平锁释放时,最后都要写一个volatile变量state。
- 公平锁获取时,首先会去读volatile变量。
- 非公平锁获取时,首先会用CAS更新volatile变量,这个操作同时具有volatile读和volatile
写的内存语义。
从本文对ReentrantLock的分析可以看出,锁释放-获取的内存语义的实现至少有下面两种方式。
1)利用volatile变量的写-读所具有的内存语义。
2)利用CAS所附带的volatile读和volatile写的内存语义。
2.5.4 concurrent包的实现
由于Java的CAS同时具有volatile读和volatile写的内存语义,因此Java线程之间的通信现在有了下面4种方式。
1)A线程写volatile变量,随后B线程读这个volatile变量。
2)A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
3)A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
4)A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式。
首先,声明共享变量为volatile。
然后,使用CAS的原子条件更新来实现线程之间的同步。
同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
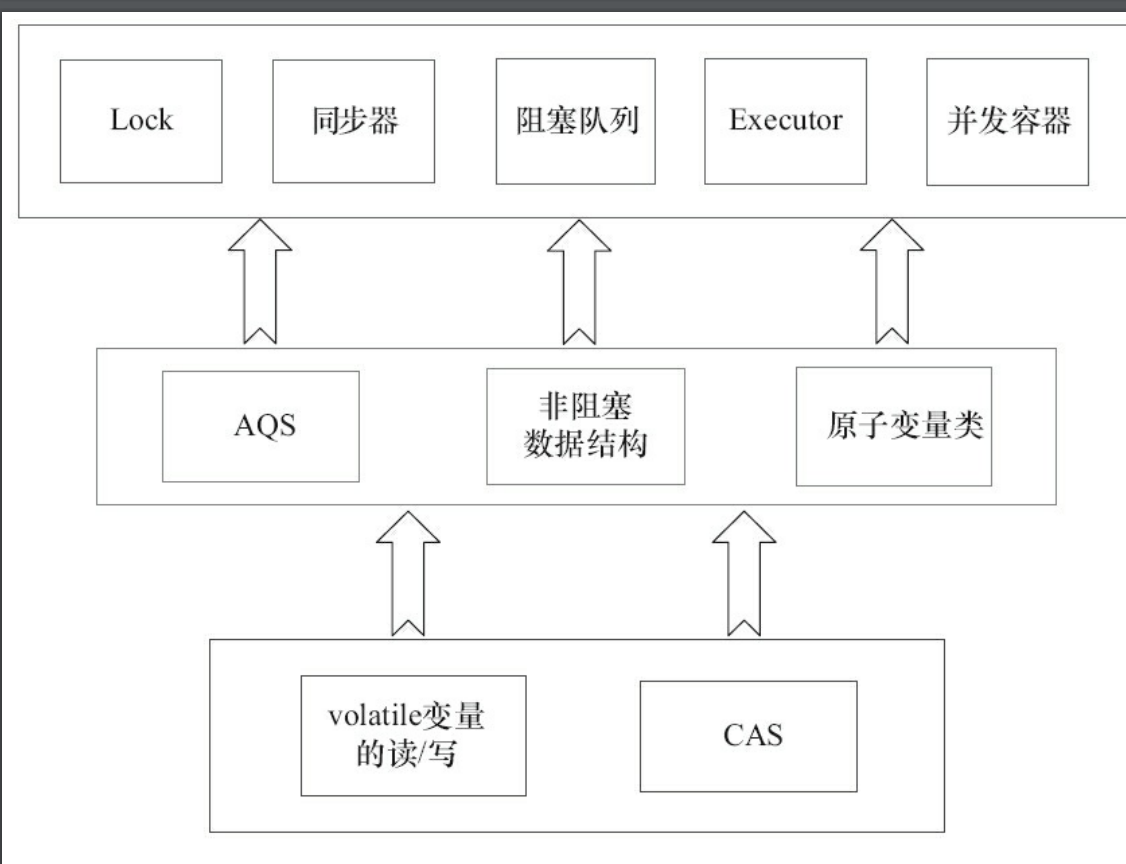
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。
2.6 final域的内存语义
3.6.1 final域的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则。
1)在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
2)初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
示例性代码
public class FinalExample {
int i; // 普通变量
final int j; // final变量
static FinalExample obj;
public FinalExample () { // 构造函数
i = 1; // 写普通域
j = 2; // 写final域
}
public static void writer () { // 写线程A执行
obj = new FinalExample ();
}
public static void reader () { // 读线程B执行
FinalExample object = obj; // 读对象引用
int a = object.i; // 读普通域
int b = object.j; // 读final域
}
}
2.6.2 写final域的重排序规则
写final域的重排序规则禁止把final域的写重排序到构造函数之外。这个规则的实现包含下面2个方面。
1)JMM禁止编译器把final域的写重排序到构造函数之外。
2)编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
现在让我们分析writer()方法。writer()方法只包含一行代码:finalExample=newFinalExample()。这行代码包含两个步骤,如下。
1)构造一个FinalExample类型的对象。
2)把这个对象的引用赋值给引用变量obj。
假设线程B读对象引用与读对象的成员域之间没有重排序
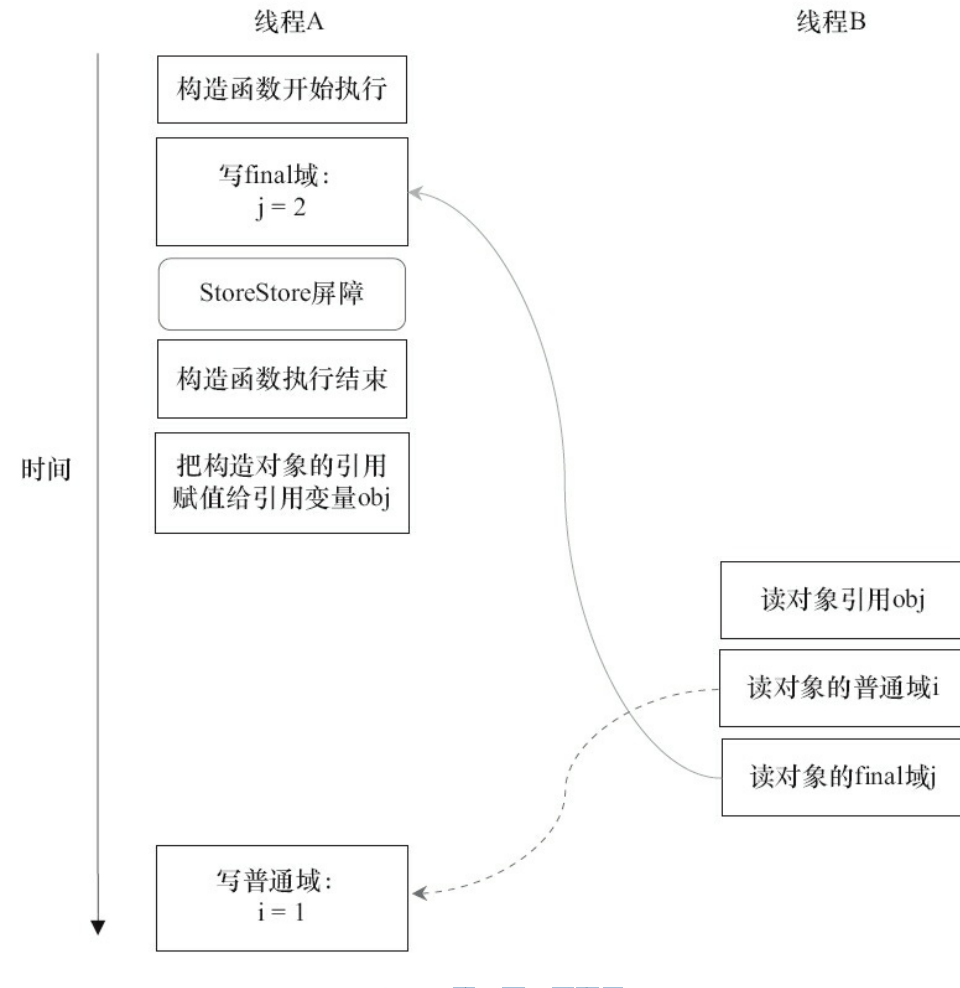
写普通域的操作被编译器重排序到了构造函数之外,读线程B错误地读取了普通变量i初始化之前的值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确地读取了final变量初始化之后的值。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。
2.6.3 读final域的重排序规则
读final域的重排序规则是,在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作。编译器会在读final域操作的前面插入一个LoadLoad屏障。
reader()方法包含3个操作。
1)初次读引用变量obj。
2)初次读引用变量obj指向对象的普通域j。
3)初次读引用变量obj指向对象的final域i。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
2.6.4 final域为引用类型
上面我们看到的final域是基础数据类型,如果final域是引用类型,将会有什么效果?
public class FinalReferenceExample {
final int[] intArray; // final是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample () { // 构造函数
intArray = new int[1]; // 1
intArray[0] = 1; // 2
}
public static void writerOne () { // 写线程A执行
obj = new FinalReferenceExample (); // 3
}
public static void writerTwo () { // 写线程B执行
obj.intArray[0] = 2; // 4
}
public static void reader () { // 读线程C执行
if (obj != null) { // 5
int temp1 = obj.intArray[0]; // 6
}
}
}
本例final域为一个引用类型,它引用一个int型的数组对象。对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
1是对final域的写入,2是对这个final域引用的对象的成员域的写入,3是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的1不能和3重排序外,2和3也不能重排序。
JMM可以确保读线程C至少能看到写线程A在构造函数中对final引用对象的成员域的写入。即C至少能看到数组下标0的值为1。而写线程B对数组元素的写入,读线程C可能看得到,也可能看不到。JMM不保证线程B的写入对读线程C可见,因为写线程B和读线程C之间存在数据竞争,此时的执行结果不可预知。
2.6.5 为什么final引用不能从构造函数内“溢出”
在构造函数内部,不能让这个被构造对象的引用为其他线程所见,也就是对象引用不能在构造函数中“溢出”。
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; // 1写final域
obj = this; // 2 this引用在此"逸出"
}
public static void writer() {
new FinalReferenceEscapeExample ();
}
public static void reader() {
if (obj != null) { // 3
int temp = obj.i; // 4
}
}
}
在构造函数返回前,被构造对象的引用不能为其他线程所见,因为此时的final域可能还没有被初始化。在构造函数返回后,任意线程都将保证能看到final域正确初始化之后的值,因为1和2操作可能进行重排序,但是2执行完别的线程可见。
2.6.6 final语义在处理器中的实现
写final域的重排序规则会要求编译器在final域的写之后,构造函数return之前插入一个StoreStore障屏。读final域的重排序规则要求编译器在读final域的操作前面插入一个LoadLoad屏障。
2.6.7 JSR-133为什么要增强final的语义
2.7 happens-before
2.7.1 JMM的设计
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上面计算圆的面积的示例代码存在3个happens-before关系,如下。
- A happens-before B。
- B happens-before C。
- A happens-before C。
在3个happens-before关系中,2和3是必需的,但1是不必要的。因此,JMM把happens-before要求禁止的重排序分为了下面两类。
1)会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。。
2)不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种重排序)。
2.7.2 happens-before的定义
happens-before:分布式系统中事件之间的偏序关系(partial ordering)。JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证。
happens-before关系的定义如下:
1)如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2)两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法。
2.7.3 happens-before规则
1)程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
2)监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
3)volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
4)传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
5)start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
6)join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操happens-before于线程A从ThreadB.join()操作成功返回。
*start()规则:*假设线程A在执行的过程中,通过执行ThreadB.start()来启动线程B;同时,假设线程A在执行ThreadB.start()之前修改了一些共享变量,线程B在开始执行后会读这些共享变量。
join()规则:。假设线程A在执行的过程中,通过执行ThreadB.join()来等待线程B终止;同时,假设线程B在终止之前修改了一些共享变量,线程A从ThreadB.join()返回后会读这些共享变量。
2.8 双重检查锁定与延迟初始化
在Java多线程程序中,有时候需要采用延迟初始化来降低初始化类和创建对象的开销。双重检查锁定是常见的延迟初始化技术,但它是一个错误的用法。
2.8.1 双重检查锁定的由来
在Java程序中,有时候可能需要推迟一些高开销的对象初始化操作,并且只有在使用这些对象时才进行初始化。
非线程安全的延迟初始化对象的示例代码。
public class UnsafeLazyInitialization {
private static Instance instance;
public static Instance getInstance() {
if (instance == null) // 1:A线程执行
instance = new Instance(); // 2:B线程执行
return instance;
}
}
在UnsafeLazyInitialization类中,假设A线程执行代码1的同时,B线程执行代码2。此时,线程A可能会看到instance引用的对象还没有完成初始化
做同步处理来实现线程安全的延迟初始化
public class SafeLazyInitialization {
private static Instance instance;
public synchronized static Instance getInstance() {
if (instance == null)
instance = new Instance();
return instance;
}
}
由于对getInstance()方法做了同步处理,synchronized将导致性能开销。如果getInstance()方法被多个线程频繁的调用,将会导致程序执行性能的下降。
通过双重检查锁定来降低同步的开销
public class DoubleCheckedLocking { // 1
private static Instance instance; // 2
public static Instance getInstance() { // 3
if (instance == null) { // 4:第一次检查
synchronized (DoubleCheckedLocking.class) { // 5:加锁
if (instance == null) // 6:第二次检查
instance = new Instance(); // 7:问题的根源出在这里
} // 8
} // 9
return instance; // 10
} // 11
}
双重检查锁定看起来似乎很完美,但这是一个错误的优化!在线程执行到第4行,代码读取到instance不为null时,instance引用的对象有可能还没有完成初始化。
2.8.2 问题的根源
前面的双重检查锁定示例代码的第7行(instance=new Singleton();)创建了一个对象。这一行代码可以分解为如下的3步。
1:分配对象的内存空间
2:初始化对象
3:设置instance指向刚分配的内存地址
上面3步中的2和3之间,可能会被重排序。
在知晓了问题发生的根源之后,我们可以想出两个办法来实现线程安全的延迟初始化。
1)不允许2和3重排序。
2)允许2和3重排序,但不允许其他线程“看到”这个重排序。
2.8.3 基于volatile的解决方案
public class SafeDoubleCheckedLocking {
private volatile static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (SafeDoubleCheckedLocking.class) {
if (instance == null){
instance = new Instance(); // instance为volatile,现在没问题了
}
}
return instance;
}
}
}
当声明对象的引用为volatile后,通过禁止图3-39中的2和3之间的重排序,来保证线程安全的延迟初始
化。
2.8.4 基于类初始化的解决方案
JVM在类的初始化阶段(即在Class被加载后,且被线程使用之前),会执行类的初始化。在执行类的初始化期间,JVM会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化。
public class InstanceFactory {
private static class InstanceHolder {
public static Instance instance = new Instance();
}
public static Instance getInstance() {
return InstanceHolder.instance ; // 这里将导致InstanceHolder类被初始化
}
}
3 Java并发编程基础
3.1 线程简介
3.1.1 什么是线程
操作系统调度的最小单元是线程,也叫轻量级进程(LightWeight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。
3.1.2 为什么要使用多线程
3.1.3 线程优先级
现代操作系统基本采用时分的形式调度运行的线程,操作系统会分出一个个时间片,线程会分配到若干时间片,当线程的时间片用完了就会发生线程调度,并等待着下次分配。线程分配到的时间片多少也就决定了线程使用处理器资源的多少,而线程优先级就是决定线程需要多或者少分配一些处理器资源的线程属性。
在Java线程中,通过一个整型成员变量priority来控制优先级,优先级的范围从1~10,在线程构建的时候可以通过setPriority(int)方法来修改优先级,默认优先级是5,优先级高的线程分配时间片的数量要多于优先级低的线程。设置线程优先级时,针对频繁阻塞(休眠或者I/O操作)的线程需要设置较高优先级,而偏重计算(需要较多CPU时间或者偏运算)的线程则设置较低的优先级,确保处理器不会被独占。
线程优先级不能作为程序正确性的依赖,在不同的JVM以及操作系统上,线程规划会存在差异,有些操作系统甚至会忽略对线程优先级的设定。
3.1.4 线程的状态
Java线程在运行的生命周期中可能6种不同的状态,在给定的一个时刻,线程只能处于其中的一个状态。

线程在自身的生命周期中,并不是固定地处于某个状态,而是随着代码的执行在不同的状态之间进行切换。
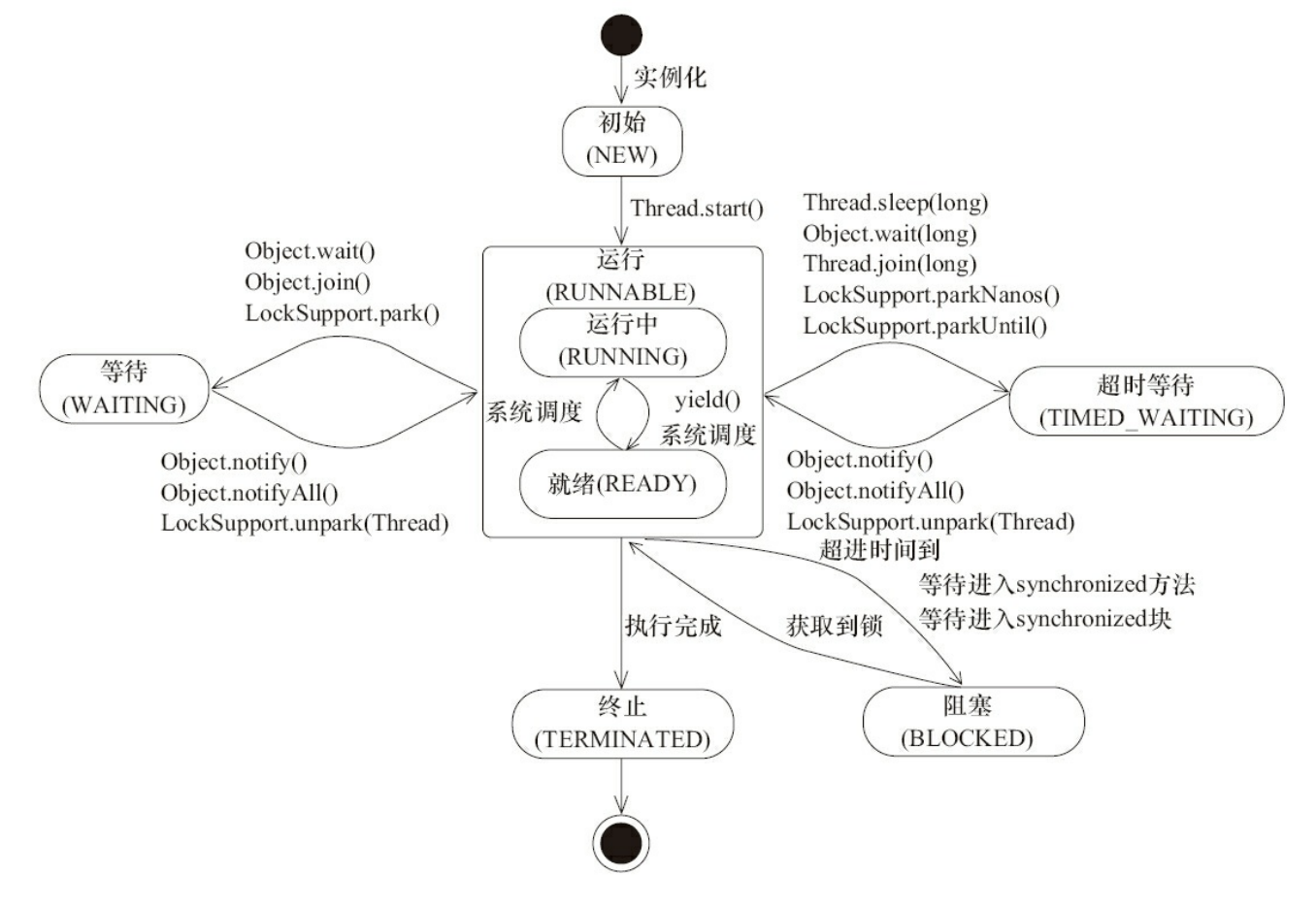
线程创建之后,调用start()方法开始运行。当线程执行wait()方法之后,线程进入等待状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而超时等待状态相当于在等待状态的基础上增加了超时限制,也就是超时时间到达时将会返回到运行状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到阻塞状态。线程在执行Runnable的run()方法之后将会进入到终止状态。
注意 Java将操作系统中的运行和就绪两个状态合并称为运行状态。阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态,但是阻塞在java.concurrent包中Lock接口的线程状态却是等待状态,因为java.concurrent包中Lock接口对于阻塞的实现均使用了LockSupport类中的相关方法。
3.1.5 Daemon线程(守护线程)
Daemon线程是一种支持型线程,因为它主要被用作程序中后台调度以及支持性工作。这意味着,当一个Java虚拟机中不存在非Daemon线程的时候,Java虚拟机将会退出。可以通过调用Thread.setDaemon(true)将线程设置为Daemon线程。
Daemon属性需要在启动线程之前设置,不能在启动线程之后设置。
Daemon线程被用作完成支持性工作,但是在Java虚拟机退出时Daemon线程中的finally块并不一定会执行。
package cm;
/**
* @author likecat
* @version 1.0
* @date 2022/8/8 16:32
*/
public class DaemonThread {
public static void main(String[] args) {
Thread thread = new Thread(new DaemonRunner(), "DaemonRunner");
thread.setDaemon(true);
thread.start();
}
static class DaemonRunner implements Runnable {
@Override
public void run() {
try {
SleepUtils.second(10);
} finally {
System.out.println("DaemonThread finally run.");
}
}
}
}
运行Daemon程序,可以看到在终端或者命令提示符上没有任何输出。main线程(非Daemon线程)在启动了线程DaemonRunner之后随着main方法执行完毕而终止,而此时Java虚拟机中已经没有非Daemon线程,虚拟机需要退出。Java虚拟机中的所有Daemon线程都需要立即终止,因此DaemonRunner立即终止,但是DaemonRunner中的finally块并没有执行。
注意 在构建Daemon线程时,不能依靠finally块中的内容来确保执行关闭或清理资源的逻辑。
3.2 启动和终止线程
3.2.1 构造线程
在运行线程之前首先要构造一个线程对象,线程对象在构造的时候需要提供线程所需要的属性,如线程所属的线程组、线程优先级、是否是Daemon线程等信息。
下面是java.lang.Thread中对线程进行初始化:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name;
//当前线程就是该线程的父线程
Thread parent = currentThread();
SecurityManager security = System.getSecurityManager();
if (g == null) {
/* Determine if it's an applet or not */
/* If there is a security manager, ask the security manager
what to do. */
if (security != null) {
g = security.getThreadGroup();
}
/* If the security doesn't have a strong opinion of the matter
use the parent thread group. */
if (g == null) {
g = parent.getThreadGroup();
}
}
/* checkAccess regardless of whether or not threadgroup is
explicitly passed in. */
g.checkAccess();
/*
* Do we have the required permissions?
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
g.addUnstarted();
this.group = g;
// 将daemon、priority属性设置为父线程的对应属性
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader();
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
this.target = target;
setPriority(priority);
// 将父线程的InheritableThreadLocal复制过来
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
/* Set thread ID 分配一个线程ID */
tid = nextThreadID();
}
一个新构造的线程对象是由其parent线程来进行空间分配的,而child线程继承了parent是否为Daemon、优先级和加载资源的contextClassLoader以及可继承的ThreadLocal,同时还会分配一个唯一的ID来标识这个child线程。至此,一个能够运行的线程对象就初始化好了,在堆内存中等待着运行。
3.2.2 启动线程
线程对象在初始化完成之后,调用start()方法就可以启动这个线程。线程start()方法的含义是:当前线程(即parent线程)同步告知Java虚拟机,只要线程规划器空闲,应立即启动调用start()方法的线程。
注意 启动一个线程前,最好为这个线程设置线程名称,因为这样在使用jstack分析程序或者进行问题排查时,就会给开发人员提供一些提示,自定义的线程最好能够起个名字。
3.2.3 理解中断
中断可以理解为线程的一个标识位属性,它表示一个运行中的线程是否被其他线程进行了中断操作。中断好比其他线程对该线程打了个招呼,其他线程通过调用该线程的**interrupt()**方法对其进行中断操作。
线程通过检查自身是否被中断来进行响应,线程通过方法isInterrupted()来进行判断是否被中断,也可以调用静态方法Thread.interrupted()对当前线程的中断标识位进行复位。如果该线程已经处于终结状态,即使该线程被中断过,在调用该线程对象的isInterrupted()时依旧会返回false。
从Java的API中可以看到,许多声明抛出InterruptedException的方法(例如Thread.sleep(long
millis)方法)这些方法在抛出InterruptedException之前,Java虚拟机会先将该线程的中断标识位清除,然后抛出InterruptedException,此时调用isInterrupted()方法将会返回false。
在下述例子中,首先创建了两个线程,SleepThread和BusyThread,前者不停地睡眠,后者一直运行,然后对这两个线程分别进行中断操作,观察二者的中断标识位。
package cm;
import java.util.concurrent.TimeUnit;
/**
* @author likecat
* @version 1.0
* @date 2022/8/8 18:08
*/
public class Interrupted {
public static void main(String[] args) throws Exception {
// sleepThread不停的尝试睡眠
Thread sleepThread = new Thread(new SleepRunner(), "SleepThread");
sleepThread.setDaemon(true);
// busyThread不停的运行
Thread busyThread = new Thread(new BusyRunner(), "BusyThread");
busyThread.setDaemon(true);
sleepThread.start();
busyThread.start();
// 休眠5秒,让sleepThread和busyThread充分运行
TimeUnit.SECONDS.sleep(5);
sleepThread.interrupt();
busyThread.interrupt();
System.out.println("SleepThread interrupted is " + sleepThread.isInterrupted());
System.out.println("BusyThread interrupted is " + busyThread.isInterrupted());
// 防止sleepThread和busyThread立刻退出
SleepUtils.second(2);
}
static class SleepRunner implements Runnable {
@Override
public void run() {
while (true) {
SleepUtils.second(10);
}
}
}
static class BusyRunner implements Runnable {
@Override
public void run() {
while (true) {
}
}
}
}
输出:
SleepThread interrupted is false
BusyThread interrupted is true
从结果可以看出,抛出InterruptedException的线程SleepThread,其中断标识位被清除了,而一直忙碌运作的线程BusyThread,中断标识位没有被清除。
3.2.4 过期的suspend()、resume()和stop()
在下面所示的例子中,创建了一个线程PrintThread,它以1秒的频率进行打印,而主线程对其进行暂停、恢复和停止操作。
package cm;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeUnit;
/**
* @author likecat
* @version 1.0
* @date 2022/8/9 11:14
*/
public class Deprecated {
public static void main(String[] args) throws Exception {
DateFormat format = new SimpleDateFormat("HH:mm:ss");
Thread printThread = new Thread(new Runner(), "PrintThread");
printThread.setDaemon(true);
printThread.start();
TimeUnit.SECONDS.sleep(3);
// 将PrintThread进行暂停,输出内容工作停止
printThread.suspend();
System.out.println("main suspend PrintThread at " + format.format(new Date());
TimeUnit.SECONDS.sleep(3);
// 将PrintThread进行恢复,输出内容继续
printThread.resume();
System.out.println("main resume PrintThread at " + format.format(new Date()));
TimeUnit.SECONDS.sleep(3);
// 将PrintThread进行终止,输出内容停止
printThread.stop();
System.out.println("main stop PrintThread at " + format.format(new Date()));
TimeUnit.SECONDS.sleep(3);
}
static class Runner implements Runnable {
@Override
public void run() {
DateFormat format = new SimpleDateFormat("HH:mm:ss");
while (true) {
System.out.println(Thread.currentThread().getName() + " Run at " +
format.format(new Date()));
SleepUtils.second(1);
}
}
}
}
在执行过程中,PrintThread运行了3秒,随后被暂停,3秒后恢复,最后经过3秒被终止。通过示例的输出可以看到,suspend()、resume()和stop()方法完成了线程的暂停、恢复和终止工作,而且非常“人性化”。但是这些API是过期的,也就是不建议使用的。
不建议使用的原因主要有:以suspend()方法为例,在调用后,线程不会释放已经占有的资源(比如锁),而是占有着资源进入睡眠状态,这样容易引发死锁问题。同样,stop()方法在终结一个线程时不会保证线程的资源正常释放,通常是没有给予线程完成资源释放工作的机会,因此会导致程序可能工作在不确定状态下。
暂停和恢复操作可以用后面提到的等待/通知机制来替代。
3.2.5 安全地终止线程
中断状态是线程的一个标识位,而中断操作是一种简便的线程间交互方式,而这种交互方式最适合用来取消或停止任务。除了中断以外,还可以利用一个boolean变量来控制是否需要停止任务并终止该线程。
在下面所示的例子中,创建了一个线程CountThread,它不断地进行变量累加,而主线程尝试对其进行中断操作和停止操作。
package cm;
import java.util.concurrent.TimeUnit;
/**
* @author likecat
* @version 1.0
* @date 2022/8/9 11:21
*/
public class Shutdown {
public static void main(String[] args) throws Exception {
Runner one = new Runner();
Thread countThread = new Thread(one, "CountThread");
countThread.start();
// 睡眠1秒,main线程对CountThread进行中断,使CountThread能够感知中断而结束
TimeUnit.SECONDS.sleep(1);
countThread.interrupt();
Runner two = new Runner();
countThread = new Thread(two, "CountThread");
countThread.start();
// 睡眠1秒,main线程对Runner two进行取消,使CountThread能够感知on为false而结束
TimeUnit.SECONDS.sleep(1);
two.cancel();
}
private static class Runner implements Runnable {
private long i;
private volatile boolean on = true;
@Override
public void run() {
while (on && !Thread.currentThread().isInterrupted()){
i++;
}
System.out.println("Count i = " + i);
}
public void cancel() {
on = false;
}
}
}
main线程通过中断操作和cancel()方法均可使CountThread得以终止。这种通过标识位或者中断操作的方式能够使线程在终止时有机会去清理资源,而不是武断地将线程停止,因此这种终止线程的做法显得更加安全和优雅。
3.3 线程间通信
3.3.1 volatile和synchronized关键字
Java支持多个线程同时访问一个对象或者对象的成员变量,由于每个线程可以拥有这个变量的拷贝(虽然对象以及成员变量分配的内存是在共享内存中的,但是每个执行的线程还是可以拥有一份拷贝,这样做的目的是加速程序的执行),所以程序在执行过程中,一个线程看到的变量并不一定是最新的。
关键字volatile可以用来修饰字段(成员变量),就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性。
关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。
任意一个对象都拥有自己的监视器,当这个对象由同步块或者这个对象的同步方法调用时,执行方法的线程必须先获取到该对象的监视器才能进入同步块或者同步方法,而没有获取到监视器(执行该方法)的线程将会被阻塞在同步块和同步方法的入口处,进入BLOCKED状态。无论采用哪种方式,其本质是对一个对象的监视器(monitor)进行获取,而这个获取过程是排他的,也就是同一时刻只能有一个线程获取到由synchronized所保护对象的监视器。
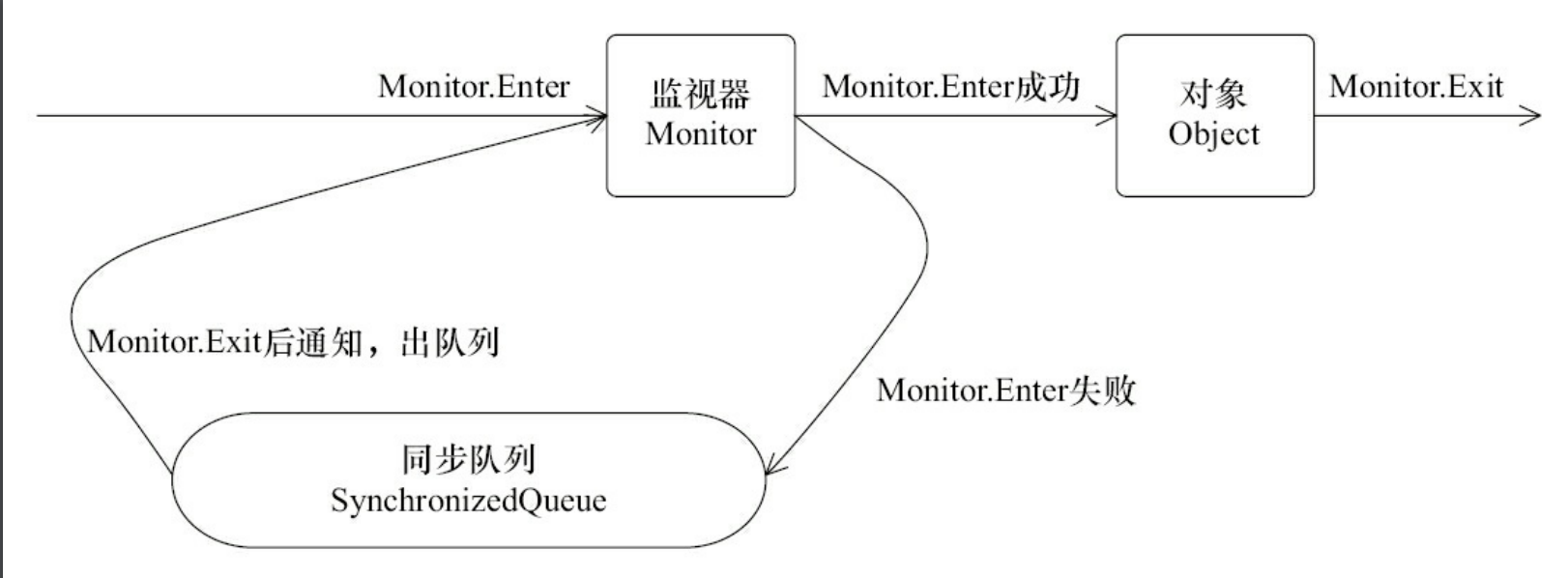
从图中可以看到,任意线程对Object(Object由synchronized保护)的访问,首先要获得Object的监视器。如果获取失败,线程进入同步队列,线程状态变为BLOCKED。当访问Object的前驱(获得了锁的线程)释放了锁,则该释放操作唤醒阻塞在同步队列中的线程,使其重新尝试对监视器的获取。
3.3.2 等待/通知机制
等待/通知的相关方法是任意Java对象都具备的,因为这些方法被定义在所有对象的超类java.lang.Object上。

等待/通知机制,是指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B调用了对象O的notify()或者notifyAll()方法,线程A收到通知后从对象O的wait()方法返回,进而执行后续操作。上述两个线程通过对象O来完成交互,而对象上的wait()和notify/notifyAll()的关系就如同开关信号一样,用来完成等待方和通知方之间的交互工作。
调用wait()、notify()以及notifyAll()时需要注意的细节,如下。
1)使用wait()、notify()和notifyAll()时需要先对调用对象加锁。
2)调用wait()方法后,线程状态由RUNNING变为WAITING,并将当前线程放置到对象的等待队列。
3)notify()或notifyAll()方法调用后,等待线程依旧不会从wait()返回,需要调用notify()或notifAll()的线程释放锁之后,等待线程才有机会从wait()返回。
4)notify()方法将等待队列中的一个等待线程从等待队列中移到同步队列中,而notifyAll()方法则是将等待队列中所有的线程全部移到同步队列,被移动的线程状态由WAITING变为BLOCKED。
5)从wait()方法返回的前提是获得了调用对象的锁。
等待/通知机制依托于同步机制,其目的就是确保等待线程从wait()方法返回时能够感知到通知线程对变量做出的修改。
3.3.3 等待/通知的经典范式
该范式分为两部分,分别针对等待方(消费者)和通知方(生产者)。
等待方遵循如下原则。
1)获取对象的锁。
2)如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件。
3)条件满足则执行对应的逻辑。
synchronized(对象) {
while(条件不满足) {
对象.wait();
}
对应的处理逻辑
}
通知方遵循如下原则。
1)获得对象的锁。
2)改变条件。
3)通知所有等待在对象上的线程。
synchronized(对象) {
改变条件
对象.notifyAll();
}
3.3.4 管道输入/输出流
管道输入/输出流和普通的文件输入/输出流或者网络输入/输出流不同之处在于,它主要用于线程之间的数据传输,而传输的媒介为内存。
管道输入/输出流主要包括了如下4种具体实现:PipedOutputStream、PipedInputStream、PipedReader和PipedWriter,前两种面向字节,而后两种面向字符。
示例代码如下,创建了printThread,它用来接受main线程的输入,任何main线程的输入均通过PipedWriter写入,而printThread在另一端通过PipedReader将内容读出并打印。
package cm;
import java.io.IOException;
import java.io.PipedReader;
import java.io.PipedWriter;
/**
* @author likecat
* @version 1.0
* @date 2022/8/9 15:25
*/
public class Piped {
public static void main(String[] args) throws Exception {
PipedWriter out = new PipedWriter();
PipedReader in = new PipedReader();
// 将输出流和输入流进行连接,否则在使用时会抛出IOException
out.connect(in);
Thread printThread = new Thread(new Print(in), "PrintThread");
printThread.start();
int receive = 0;
try {
while ((receive = System.in.read()) != -1) {
out.write(receive);
}
} finally {
out.close();
}
}
static class Print implements Runnable {
private PipedReader in;
public Print(PipedReader in) {
this.in = in;
}
public void run() {
int receive = 0;
try {
while ((receive = in.read()) != -1) {
System.out.print((char) receive);
}
} catch (IOException ex) {
}
}
}
}
对于Piped类型的流,必须先要进行绑定,也就是调用connect()方法,如果没有将输入/输出流绑定起来,对于该流的访问将会抛出异常。
3.3.5 Thread.join()的使用
如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才从thread.join()返回。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时时间没有终止,那么将会从该超时方法中返回。
在下面所示的例子中,创建了10个线程,编号0~9,每个线程调用前一个线程的join()方法,也就是线程0结束了,线程1才能从join()方法中返回,而线程0需要等待main线程结束。
package cm;
import java.util.concurrent.TimeUnit;
/**
* @author likecat
* @version 1.0
* @date 2022/8/9 15:37
*/
public class Join {
public static void main(String[] args) throws Exception {
Thread previous = Thread.currentThread();
for (int i = 0; i < 10; i++) {
// 每个线程拥有前一个线程的引用,需要等待前一个线程终止,才能从等待中返回
Thread thread = new Thread(new Domino(previous), String.valueOf(i));
thread.start();
previous = thread;
}
TimeUnit.SECONDS.sleep(5);
System.out.println(Thread.currentThread().getName() + " terminate.");
}
static class Domino implements Runnable {
private Thread thread;
public Domino(Thread thread) {
this.thread = thread;
}
public void run() {
try {
thread.join();
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName() + " terminate.");
}
}
}
每个线程终止的前提是前驱线程的终止,每个线程等待前驱线程终止后,才从join()方法返回,这里涉及了等待/通知机制(等待前驱线程结束,接收前驱线程结束通知)。
当线程终止时,会调用线程自身的notifyAll()方法,会通知所有等待在该线程对象上的线程。可以看到join()方法的逻辑结构,即加锁、循环和处理逻辑3个步骤。
3.3.6 ThreadLocal的使用
ThreadLocal,即线程变量,是一个以ThreadLocal对象为键、任意对象为值的存储结构。这个结构被附带在线程上,也就是说一个线程可以根据一个ThreadLocal对象查询到绑定在这个线程上的一个值。
可以通过set(T)方法来设置一个值,在当前线程下再通过get()方法获取到原先设置的值。
在下面所示的例子中,构建了一个常用的Profiler类,它具有begin()和end()两个方法,而end()方法返回从begin()方法调用开始到end()方法被调用时的时间差,单位是毫秒。
package cm;
import java.util.concurrent.TimeUnit;
/**
* @author likecat
* @version 1.0
* @date 2022/8/9 16:56
*/
public class Profiler {
// 第一次get()方法调用时会进行初始化(如果set方法没有调用),每个线程会调用一次
private static final ThreadLocal<Long> TIME_THREADLOCAL = new ThreadLocal<Long>() {
protected Long initialValue() {
return System.currentTimeMillis();
}
};
public static final void begin() {
TIME_THREADLOCAL.set(System.currentTimeMillis());
}
public static final long end() {
return System.currentTimeMillis() - TIME_THREADLOCAL.get();
}
public static void main(String[] args) throws Exception {
Profiler.begin();
TimeUnit.SECONDS.sleep(1);
System.out.println("Cost: " + Profiler.end() + " mills");
}
}
3.4 线程应用实例
3.4.1 等待超时模式
等待超时模式的伪代码如下。
// 对当前对象加锁
public synchronized Object get(long mills) throws InterruptedException {
long future = System.currentTimeMillis() + mills;
long remaining = mills;
// 当超时大于0并且result返回值不满足要求
while ((result == null) && remaining > 0) {
wait(remaining);
remaining = future - System.currentTimeMillis();
}
return result;
}
3.4.2 一个简单的数据库连接池示例
链接:数据库连接池示例
3.4.3 线程池技术及其示例
面对成千上万的任务递交进服务器时,如果还是采用一个任务一个线程的方式,那么将会创建数以万记的线程,这不是一个好的选择。因为这会使操作系统频繁的进行线程上下文切换,无故增加系统的负载,而线程的创建和消亡都是需要耗费系统资源的,也无疑浪费了系统资源。
线程池技术能够很好地解决这个问题,它预先创建了若干数量的线程,并且不能由用户直接对线程的创建进行控制,在这个前提下重复使用固定或较为固定数目的线程来完成任务的执行。这样做的好处是,一方面,消除了频繁创建和消亡线程的系统资源开销,另一方面,面对过量任务的提交能够平缓的劣化。
下面先看一个简单的线程池接口定义,示例如下:
package cm;
/**
* @author likecat
* @version 1.0
* @date 2022/8/10 11:35
*/
public interface ThreadPool<Job extends Runnable> {
// 执行一个Job,这个Job需要实现Runnable
void execute(Job job);
// 关闭线程池
void shutdown();
// 增加工作者线程
void addWorkers(int num);
// 减少工作者线程
void removeWorker(int num);
// 得到正在等待执行的任务数量
int getJobSize();
}
客户端可以通过execute(Job)方法将Job提交入线程池执行,而客户端自身不用等待Job的执行完成。除了execute(Job)方法以外,线程池接口提供了增大/减少工作者线程以及关闭线程池的方法。这里工作者线程代表着一个重复执行Job的线程,而每个由客户端提交的Job都将进入到一个工作队列中等待工作者线程的处理。
package cm;
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
/**
* @author likecat
* @version 1.0
* @date 2022/8/10 11:38
*/
public class DefaultThreadPool<Job extends Runnable> implements ThreadPool<Job> {
// 线程池最大限制数
private static final int MAX_WORKER_NUMBERS = 10;
// 线程池默认的数量
private static final int DEFAULT_WORKER_NUMBERS = 5;
// 线程池最小的数量
private static final int MIN_WORKER_NUMBERS = 1;
// 这是一个工作列表,将会向里面插入工作
private final LinkedList<Job> jobs = new LinkedList<Job>();
// 工作者列表
private final List<Worker> workers = Collections.synchronizedList(new ArrayList<Worker>());
// 工作者线程的数量
private int workerNum = DEFAULT_WORKER_NUMBERS;
// 线程编号生成
private AtomicLong threadNum = new AtomicLong();
public DefaultThreadPool() {
initializeWokers(DEFAULT_WORKER_NUMBERS);
}
public DefaultThreadPool(int num) {
workerNum = num > MAX_WORKER_NUMBERS ? MAX_WORKER_NUMBERS : num < MIN_WORKER_NUMBERS ? MIN_WORKER_NUMBERS : num;
initializeWokers(workerNum);
}
public void execute(Job job) {
if (job != null) {
// 添加一个工作,然后进行通知
synchronized (jobs) {
jobs.addLast(job);
jobs.notify();
}
}
}
public void shutdown() {
for (Worker worker : workers) {
worker.shutdown();
}
}
public void addWorkers(int num) {
synchronized (jobs) {
// 限制新增的Worker数量不能超过最大值
if (num + this.workerNum > MAX_WORKER_NUMBERS) {
num = MAX_WORKER_NUMBERS - this.workerNum;
}
initializeWokers(num);
this.workerNum += num;
}
}
public void removeWorker(int num) {
synchronized (jobs) {
if (num >= this.workerNum) {
throw new IllegalArgumentException("beyond workNum");
}
// 按照给定的数量停止Worker
int count = 0;
while (count < num) {
Worker worker = workers.get(count);
if (workers.remove(worker)) {
worker.shutdown();
count++;
}
}
this.workerNum -= count;
}
}
public int getJobSize() {
return jobs.size();
}
// 初始化线程工作者
private void initializeWokers(int num) {
for (int i = 0; i < num; i++) {
Worker worker = new Worker();
workers.add(worker);
Thread thread = new Thread(worker, "ThreadPool-Worker-" + threadNum.incrementAndGet());
thread.start();
}
}
// 工作者,负责消费任务
class Worker implements Runnable {
// 是否工作
private volatile boolean running = true;
public void run() {
while (running) {
Job job = null;
synchronized (jobs) {
// 如果工作者列表是空的,那么就wait
while (jobs.isEmpty()) {
try {
jobs.wait();
} catch (InterruptedException ex) {
// 感知到外部对WorkerThread的中断操作,返回
Thread.currentThread().interrupt();
return;
}
}
// 取出一个Job
job = jobs.removeFirst();
}
if (job != null) {
try {
job.run();
} catch (Exception ex) {
// 忽略Job执行中的Exception
}
}
}
}
public void shutdown() {
running = false;
}
}
}
从线程池的实现可以看到,当客户端调用execute(Job)方法时,会不断地向任务列表jobs中添加Job,而每个工作者线程会不断地从jobs上取出一个Job进行执行,当jobs为空时,工作者线程进入等待状态。
添加一个Job后,对工作队列jobs调用了其notify()方法,而不是notifyAll()方法,因为能够确定有工作者线程被唤醒,这时使用notify()方法将会比notifyAll()方法获得更小的开销(避免将等待队列中的线程全部移动到阻塞队列中)。
可以看到,线程池的本质就是使用了一个线程安全的工作队列连接工作者线程和客户端线程,客户端线程将任务放入工作队列后便返回,而工作者线程则不断地从工作队列上取出工作并执行。当工作队列为空时,所有的工作者线程均等待在工作队列上,当有客户端提交了一个任务之后会通知任意一个工作者线程,随着大量的任务被提交,更多的工作者线程会被唤醒。